VGG块网络
VGG块网络
——可定制的AlexNet
VGG块
经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。
而一个 VGG 块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。在最初的 VGG 论文 [Simonyan & Zisserman, 2014] 中,作者使用了带有 $3\times3$ 卷积核、填充为 1(保持高度和宽度)的卷积层,和带有 $2 \times 2$ 池化窗口、步幅为 2(每个块后的分辨率减半)的最大汇聚层。在下面的代码中,我们定义了一个名为 vgg_block 的函数来实现一个 VGG 块。
import torch |
def vgg_block(num_convs, in_channels, out_channels): |
VGG网络
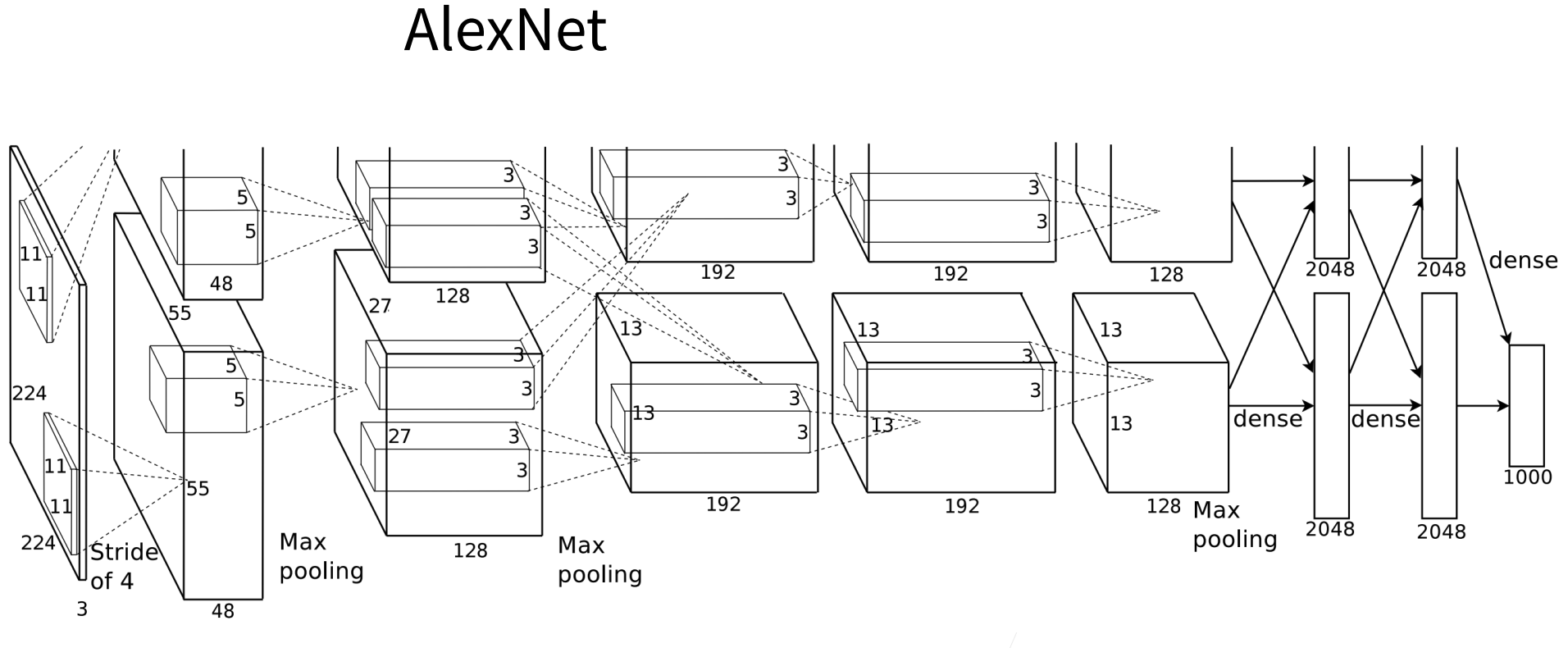
与 AlexNet、LeNet 一样,VGG 网络可以分为两部分:第一部分主要由卷积层和汇聚层组成,第二部分由全连接层组成。如 图7.2.1 中所示。
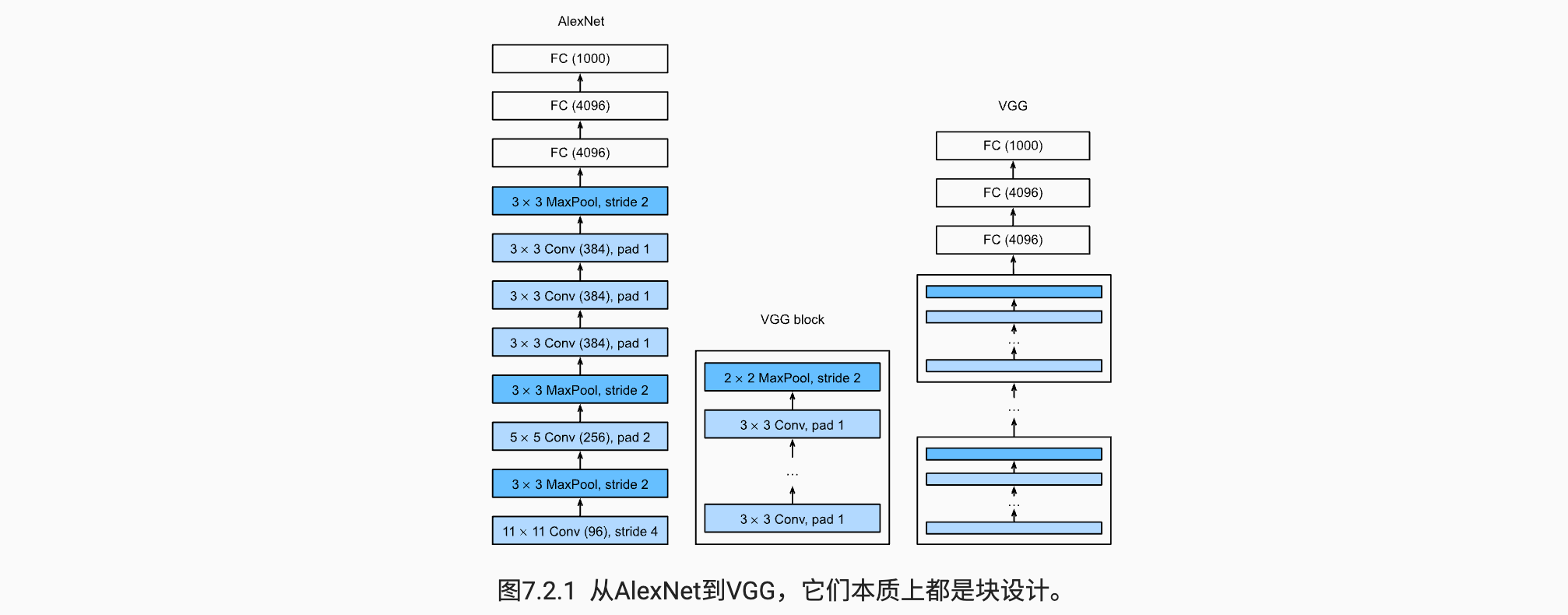
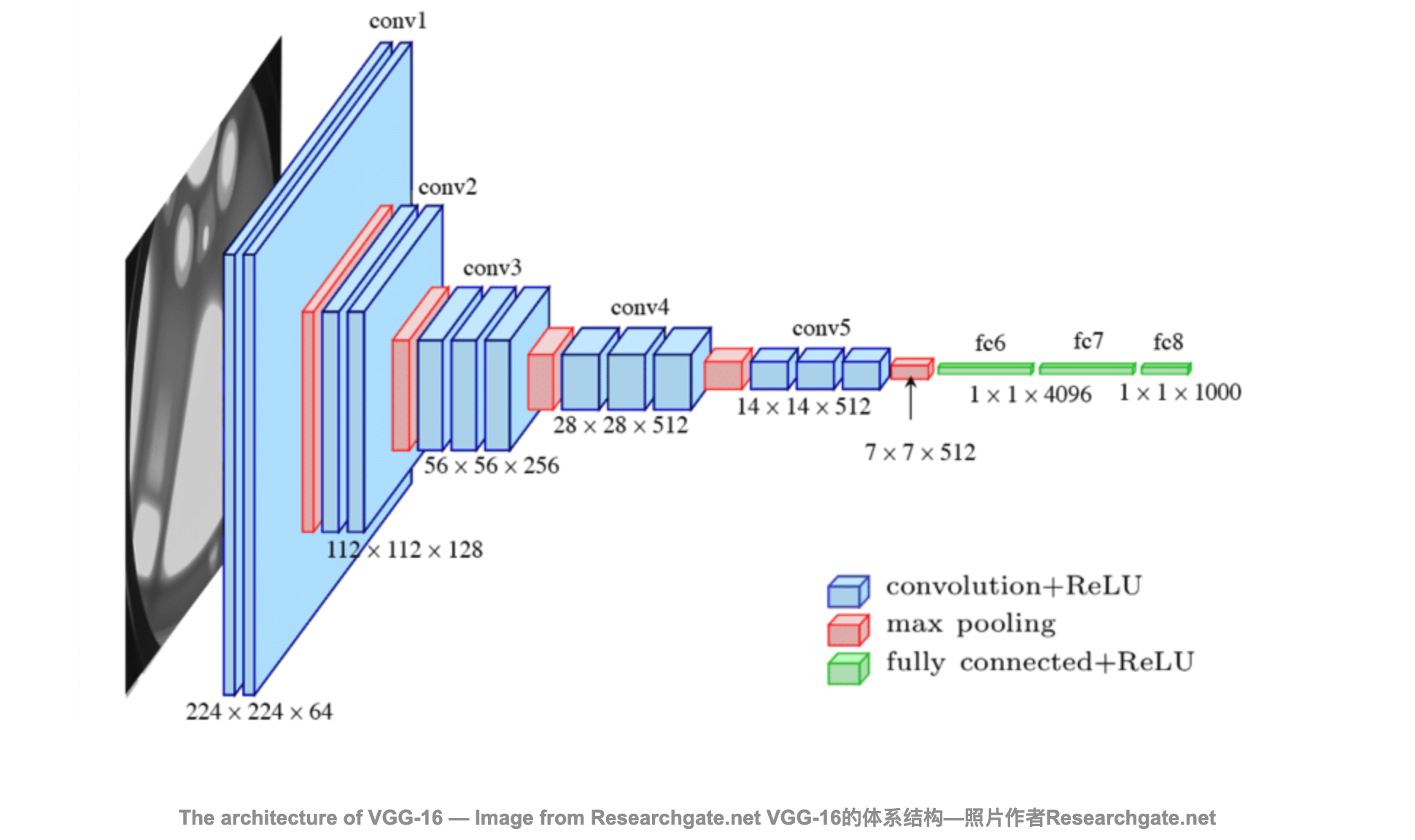
VGG神经网络连续连接 图7.2.1 的几个 VGG 块(在 vgg_block 函数中定义)。其中有超参数变量conv_arch 。该变量指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。
原始 VGG 网络有 5 个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。 第一个模块有 64 个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到 512。由于该网络使用 8 个卷积层和 3 个全连接层,因此它通常被称为 VGG-11。
总之:
- 输入通道个数 = 卷积核通道个数
- 卷积核个数 = 输出通道个数
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) |
下面的代码实现了 VGG-11。可以通过在 conv_arch 上执行 for 循环来简单实现。
def vgg(conv_arch): |
接下来,我们将构建一个高度和宽度为 224 的单通道数据样本,以观察每个层输出的形状。
X = torch.randn(size=(1, 1, 224, 224)) |
/Users/baikal/miniforge3/envs/pytorch/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ../c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
正如你所看到的,我们在每个块的高度和宽度减半,最终高度和宽度都为7。最后再展平表示,送入全连接层处理。
训练模型
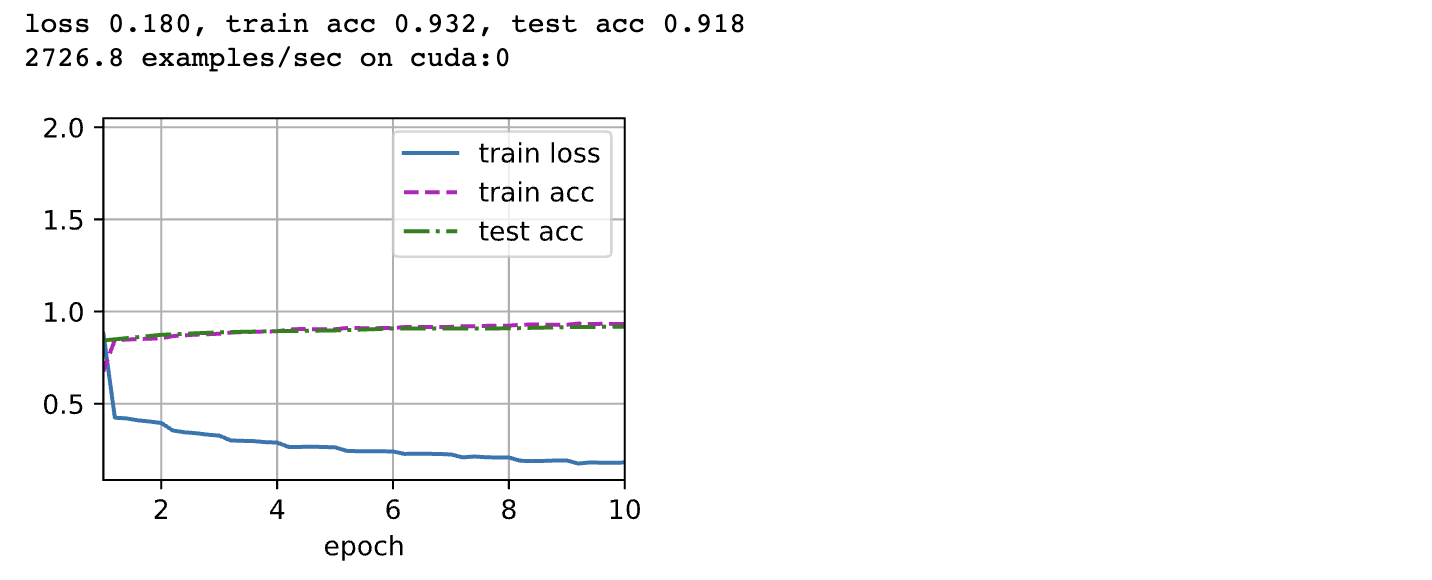
由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络,足够用于训练Fashion-MNIST数据集。
ratio = 4 |
lr, num_epochs, batch_size = 0.05, 10, 128 |
小结
VGG-11 使用可复用的卷积块构造网络。不同的 VGG 模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
在VGG论文中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即$3 \times 3$)比较浅层且宽的卷积更有效。
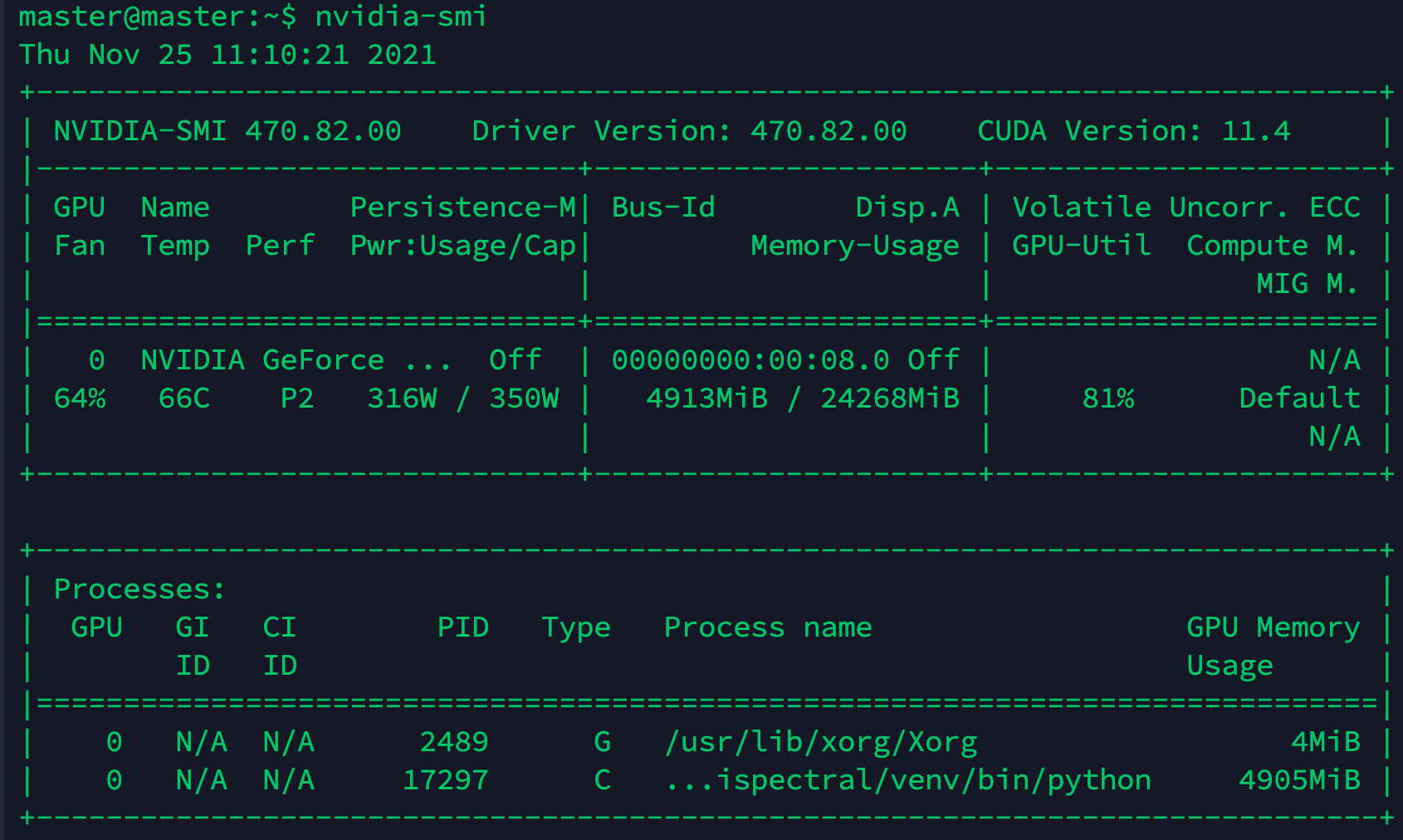
表格参数详解:
GPU:本机中的GPU编号(有多块显卡的时候,从0开始编号)图上GPU的编号是:0
Fan:风扇转速(0%-100%),N/A表示没有风扇
Name:GPU类型,图上GPU的类型是:NVIDIA
Temp:GPU的温度(GPU温度过高会导致GPU的频率下降)
Perf:GPU的性能状态,从P0(最大性能)到P12(最小性能),图上是:P2
Persistence-M:持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时花费的时间更少,图上显示的是:off
Pwr:Usager/Cap:能耗表示,Usage:用了多少,Cap总共多少
Bus-Id:GPU总线相关显示,domain:bus:device.function
Disp.A:Display Active ,表示GPU的显示是否初始化
Memory-Usage:显存使用率
Volatile GPU-Util:GPU使用率
Uncorr. ECC:关于ECC的东西,是否开启错误检查和纠正技术,0/disabled,1/enabled
Compute M:计算模式,0/DEFAULT,1/EXCLUSIVE_PROCESS,2/PROHIBITED
Processes:显示每个进程占用的显存使用率、进程号、占用的哪个GPU
显存占用和GPU占用是两个不一样的东西,显卡是由GPU和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。跑caffe代码的时候显存占得少,GPU占得多,跑TensorFlow代码的时候,显存占得多,GPU占得少。