Self-attention(下)
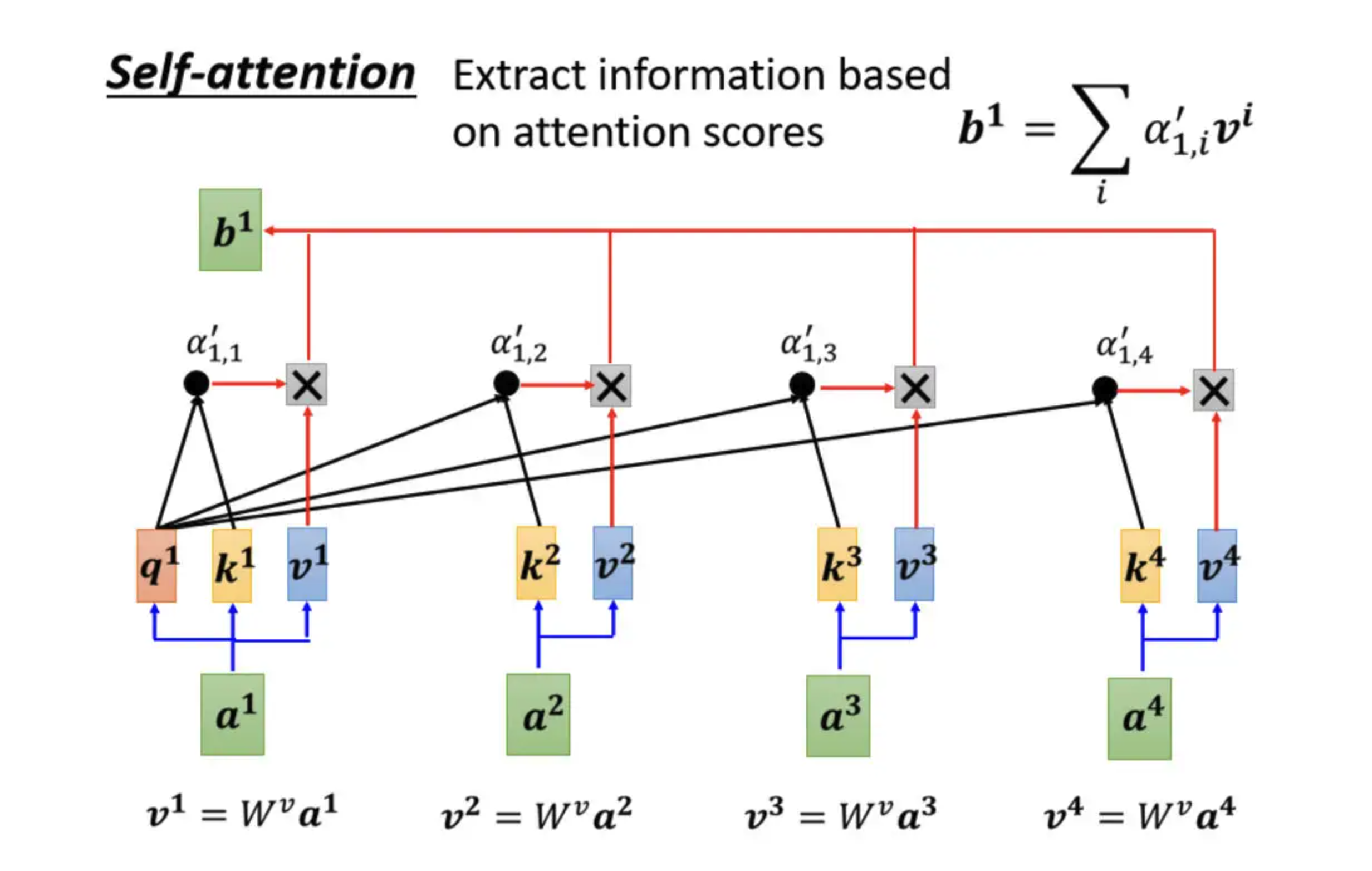
前言:self-attention(上)提到了从一排向量中获得$b^i$的方法,$b^i$用以判断各个向量的关联程度
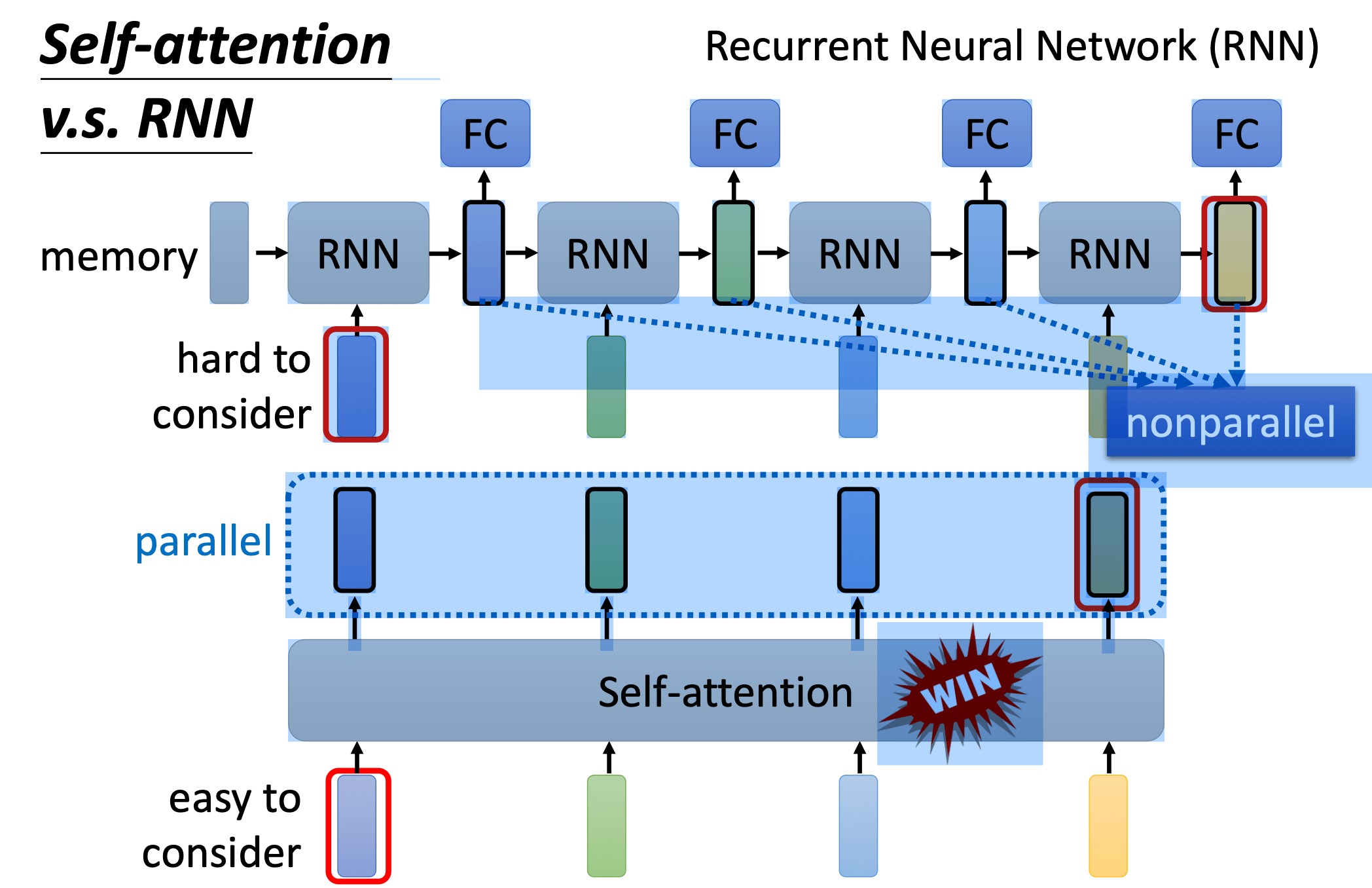
需要强调的一点是,$b^1$到$b^4$的计算是并行开始的,没有前后依赖关系,这一点也是self-attention区分于RNN(循环神经网络)的重要特征。
矩阵角度分析$b^i$的计算过程
我们已经得知每一个$a$都会产生$q、k、v$
求得$q、k、v$
$a$ 作为query时,按照流程我们要将每一个$a$都乘上一个矩阵$W^q$(是什么东西?后面提到。但可以提前说一句$W^q$其实是 network 的参数,它是在后面由学习得到的),用于求得 $q$
既然是并行的,那么就可以将这个过程组成矩阵运算,同理求 $k$、 $v$也是如此
求得$a’$
下一步是每一个 $k$的转置(横框)与每一个 $q$,计算inner product,得到该attention 的分数:
那这四个步骤的操作,可以把它拼起来,看作是矩阵跟向量相乘。于是得到 attention 分数这个步骤,如果从矩阵操作的角度来看就是以 $k^1$ 到 $k^4$ 做列,$q^1$做行进行运算:
推广到对$k^1$ 到 $k^4$ 计算 attention,$q^2$,$q^3$ ,$q^4$也要对 $k^1$ 到 $k^4$ 计算 attention。
我们会在 attention 的分数基础上进行 normalization操作,比如说对每一个 column做 softmax,让每一个 column 里面的值相加是 1。
上篇有提到过做 softmax不是唯一的选项,你完全可以选择其他的操作,比如说 ReLU 。此处通过了 softmax 以后,$a$ 的值就发生了变化,所以我们用$a′$来表示通过 softmax 以后的结果。
求得 $b^i$ (加权求和)
我们把 $v^1$ 到 $v^4$ 乘上的 α 以后,就可以得到 $b$
关于矩阵 $O$,矩阵中的每一个column,都是self-attention的输出,也就是 $b^1$ 到 $b^4$
小结
总结以上矩阵乘法,就是:
- $I$ 是self-attention的输入(input),输入值是一排向量(vector),这排向量拼接起来当作矩阵的column就是$I$
- 输入值 $I$ 分别乘上三个矩阵,$W^q , W^k, W^v$ 可以得到矩阵$Q 、 K、 V$
- 对于这三个矩阵$Q 、 K、 V$,接下来 $Q$ 乘以 $K$ 的转置,得到矩阵 $A$,对矩阵 $A$ 进行一些处理后得到 $A’$,我们叫做Attention Matrix,生成矩阵 $Q$ 就是为了得到Attention的score。
- **生成矩阵 $V$ 是为了计算最后的 $b$,也就是矩阵 $O$ **,然后接下来把 $A′$ 再乘上 $V$,就得到 $O$ 就是 Self-attention 这一层的输出
此时应该可以明白$W^q , W^k, W^v$ 是什么东西了,也就是训练数据集中数据转化而成的参数。
综上,从 $I$ 到 $O$ 就是做了 Self-attention。
Multi-head Self-attention
定义
Multi-head self-attention是self-attention的进阶版本。
回忆前面,$q$ 代表Query,它就像是使用搜寻引擎,去搜寻相关文章时的关键字。我们使用 $q$ 去寻找相关的 $k$ ,但是“相关”这个词有很多种形式,也有不同的方式去定义,因此可以定义多个 $q$ ,我们可以定义不同的 $q$ ,去负责不同种类的相关性。
具体操作方法
$q$ 有两个,那 $k$ 、 $v$ 也就要有两个。分别从 $q$ 、$k$ 、$v$ 得到 $q^1$、$q^2$, $k^1$、$k^2$,$v^1$、$v^2$。
那其实就是把 $q$ 、 $k$ 、 $v$,分别乘上两个矩阵,得到不同的 head
对另外一个位置,也做一样的事情。总之就是$q^1$在算attention 的分数的时候,就不用考虑 $k^2$了。
最后得到的$b^i$跟普通的self-attention一样,也只有一个:
也就是再乘上一个矩阵,然后得到 $b^i$,然后再送到下一层去,这个就是 Multi-head attention —— Self-attention 的变形。
Positional Encoding
对 Self-attention 而言,“天涯若比邻”恰如其分,所有的向量之间的距离都是一样的。
目前为止文章中提到的Self-attention都没有考虑向量的位置因素,在某些机遇深度学习的项目中,向量的位置可能有重要作用。例如说词性标注这个例子,也许动词出现在句首的可能性不大,所以如果我们看到某一个词汇它是放在句首的,那它是动词的可能性可能就比较低,此时的位置信息是有用的。
question:那么我们怎么提现向量的位置呢?
位置向量$e^i$
为每一个位置设定一个 vector,叫做 positional vector。每一个不同的位置,就有不同的 vector。
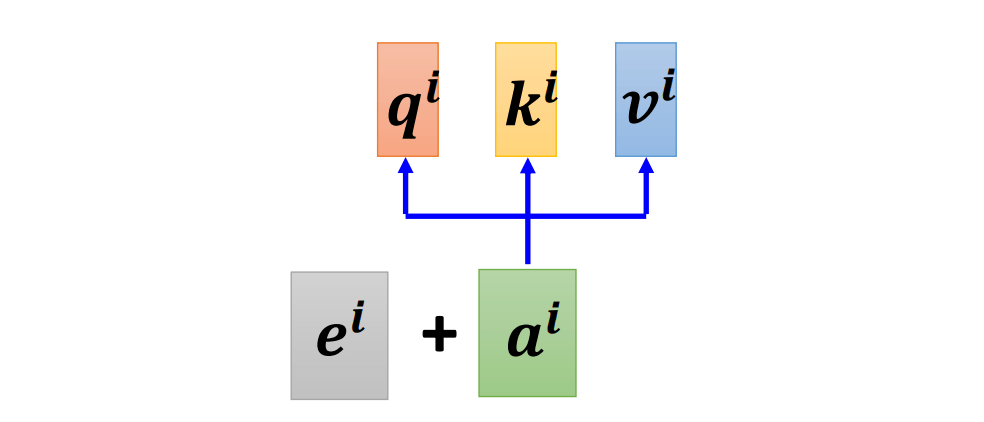
在《 Attention Is All You Need 》这篇论文中,它用的位置向量$e^i$如下所示:
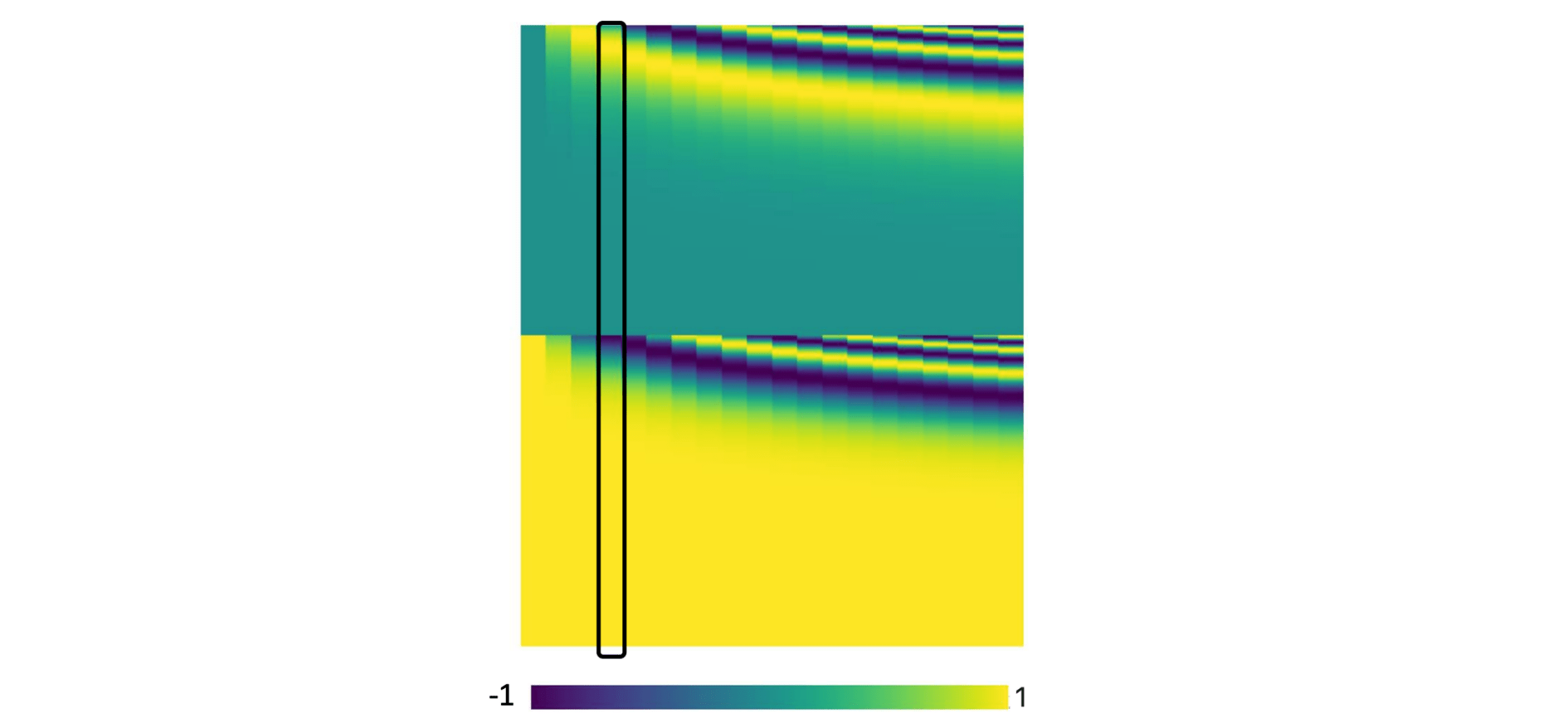
图中每一个 column 代表一个 $e$,第一个位置就是 $e^1$,第二个是位置 $e^2$,第三个位置就是 $e^3$,以此类推……
当模型在处理输入向量的时候,就可以根据 $e^i$ 知道对应的向量的位置信息。
实际上这个位置向量是人为规定的,那么可能会出现很多问题,如果只定到128位,那么当序列长度出现到129时就会出现问题
在《Attention Is All You Need paper》这篇论文里,并不存在这个问题,它的向量是由某一个规则产生的,经过一个sin、cos的函数后,得到了位置信息
可创新点:我们在进行一项新的研究时大可以发挥想象力,创造出自己的方法,甚至从数据集中学习得到。当前positional encoding仍然是一个尚待研究的问题,你永远可以提出新的做法(2021-11-06)。
推荐一篇论文,里面提出了新的positional encoding方法:Learning to Encode Position for Transformer with Continuous Dynamical Model

Applications
NLP 领域
在 NLP 领域有一个东西叫做 BERT,BERT 里面也用到 Self-attention,所以 Self-attention 在 NLP 上面的应用是比较广泛的
- 但是在用于自然语言处理时,self-attention的输入向量要做一些处理
因为由语音组成的声音信号排成一排向量时,这排向量可能会非常非常长。而每一个向量,仅仅代表了10毫米的声音信息,所以如果是 1 秒钟的声音信号,它就有 100 个向量,5 秒钟的声音,就 500 个向量,随便讲一句话,都是上千个向量。

那么对于self-attention——考虑输入序列所有的向量,就非常难顶了。
实际上我们可以知道计算attention matrix 的时候,它的计算complexity 是输入向量长度的平方
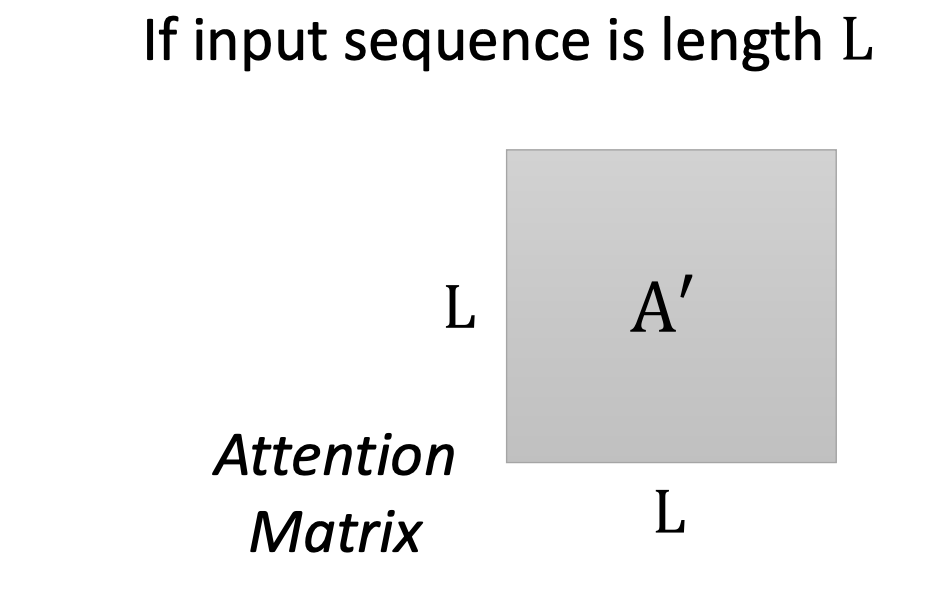
如果要按照原方案,考虑所有的向量,这就要求我们有足够大的内存,才能把这一整个矩阵存下来,这是不现实的。
所以做语音处理的时候,有一招叫做Truncated Self-attention
Truncated Self-attention
Truncated Self-attention 做的事情就是,在做 Self-attention 的时候,不要看一整句话,就只看一个小的范围就好
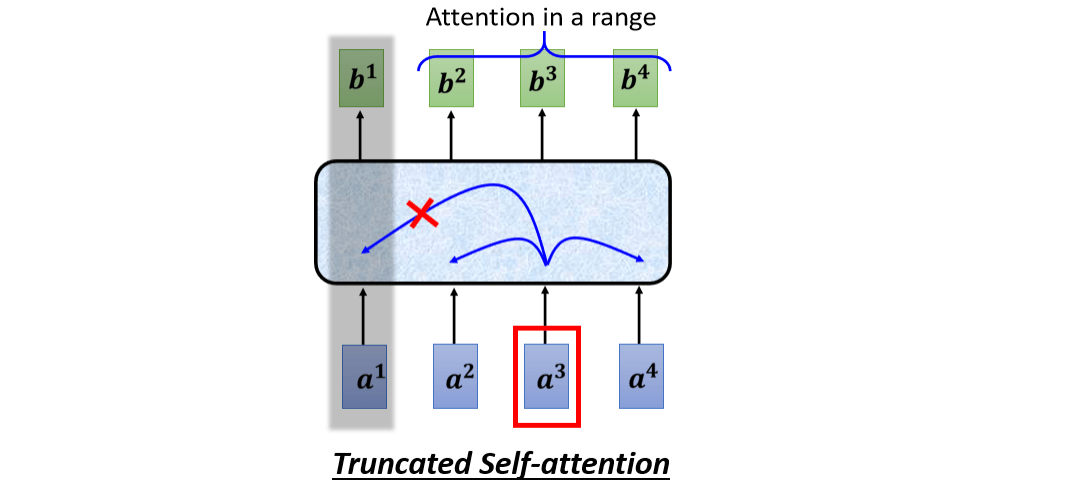
那至于这个范围应该要多大?那看个人设定了,取决于你对这个问题的理解
图像处理
我们都说 Self-attention 适用的范围是:输入是一个向量集的时候
一张图片不就是一个很长的向量嘛?然后加上RGB通道的三层之后,就是一个向量集。
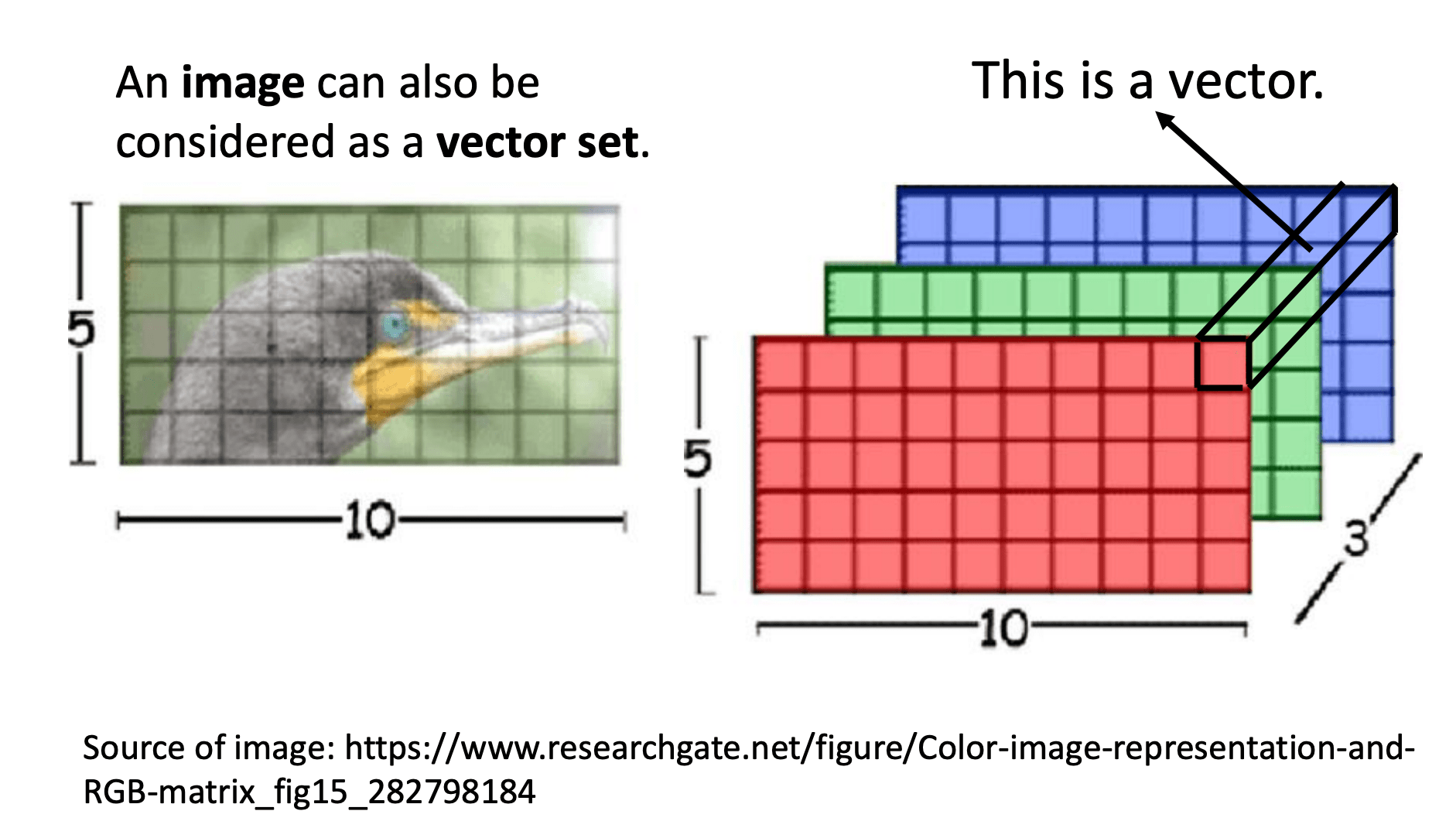
这个是一个解析度 5 *10 的图片,图片可以看作是一个 tensor,这个 tensor 的大小是 5 * 10 * 3,3 代表 RGB 三个通道。
把每一个位置的像素都看作是一个三维的向量,所以每一个像素就是一个三维的向量,那整张图片,就是 5 * 10 个向量的集合
两个使用self-attention处理图像的例子

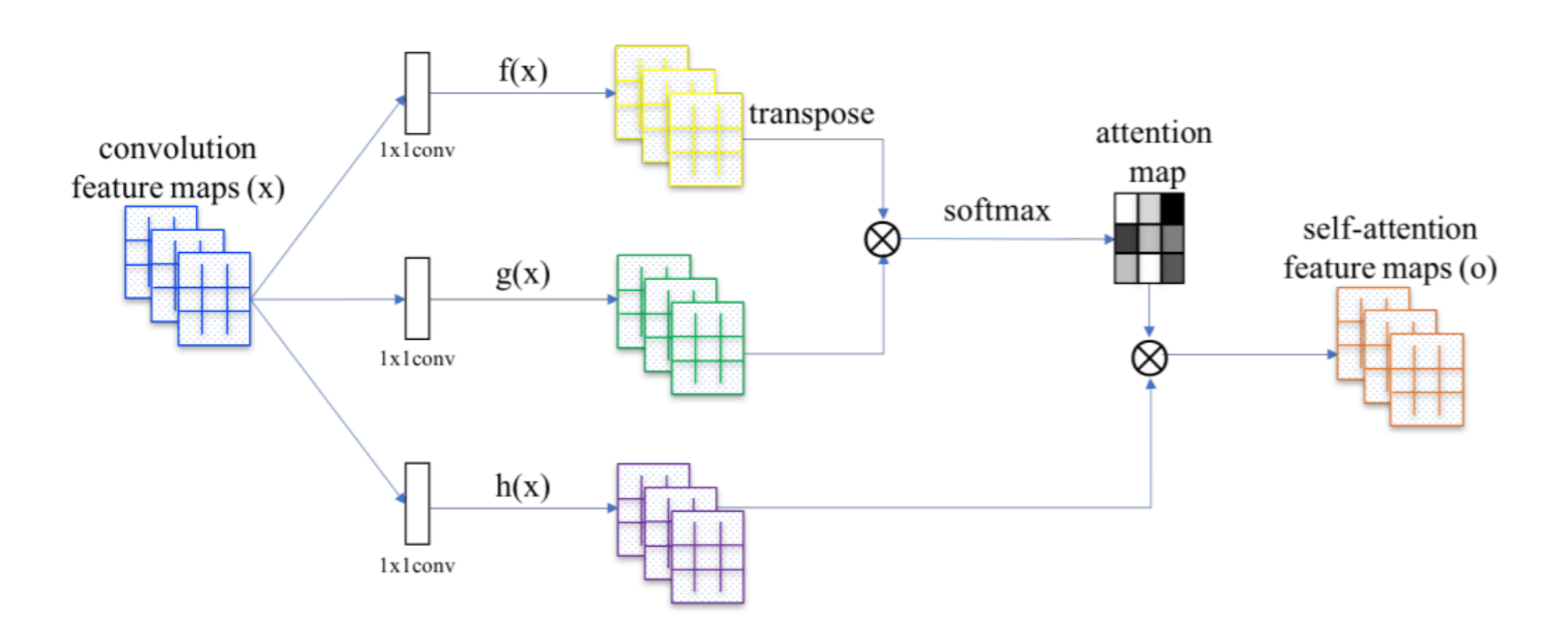

比较
Self-attention 和 CNN、RNN相比如何?
Self-attention v.s. CNN
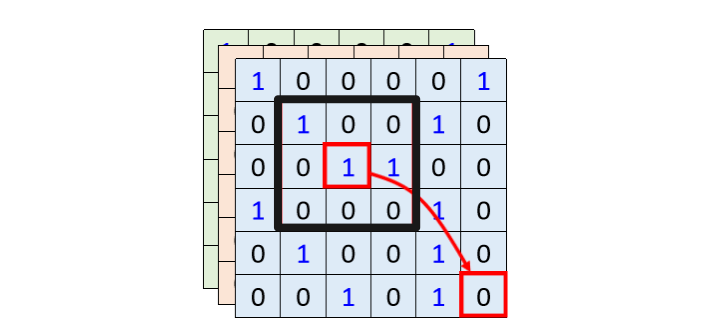
差异性
输入数据的差异
- 对于一张图片,如果用Self-attention进行处理,那么输入模型的向量就是一个个像素,要考虑的其中一个像素产生query时,其他像素产生key。同时要考虑一整张图片的信息。如果用CNN,就会画出一个receptive field,每一个神经元只考虑这个区域里的信息。
- 所以如果比较 CNN 跟 Self-attention,CNN 可以看作是一种简化版的 Self-attention,因为在做CNN的时候,我们只考虑 receptive field 里面的信息,而在做 Self-attention 的时候,我们是考虑整张图片的信息。
学习区域的差异
- 在 CNN 里面,我们要划定 receptive field,每一个神经元,只考虑 receptive field 里面的信息。receptive field 的范围跟大小,是人为决定的。
- 而对 Self-attention 而言,我们用 attention,去找出相关的 像素,就好像是 receptive field 是自动学习,network 自己决定receptive field 的形状长什么样子,network 自己决定以哪个像素为中心,哪些像素是真正需要考虑的,哪些pixel是相关的
On the Relationship,between Self-attention and Convolutional Layers
在这篇 paper 里会用数学的方式严谨的告诉你,其实CNN就是 Self-attention 的特例,Self-attention 只要设定合适的参数,它可以做到跟 CNN 一模一样的事情
所以self-attention,是更 灵活 的 CNN,而 CNN 是有受限制的 Self-attention

适用性
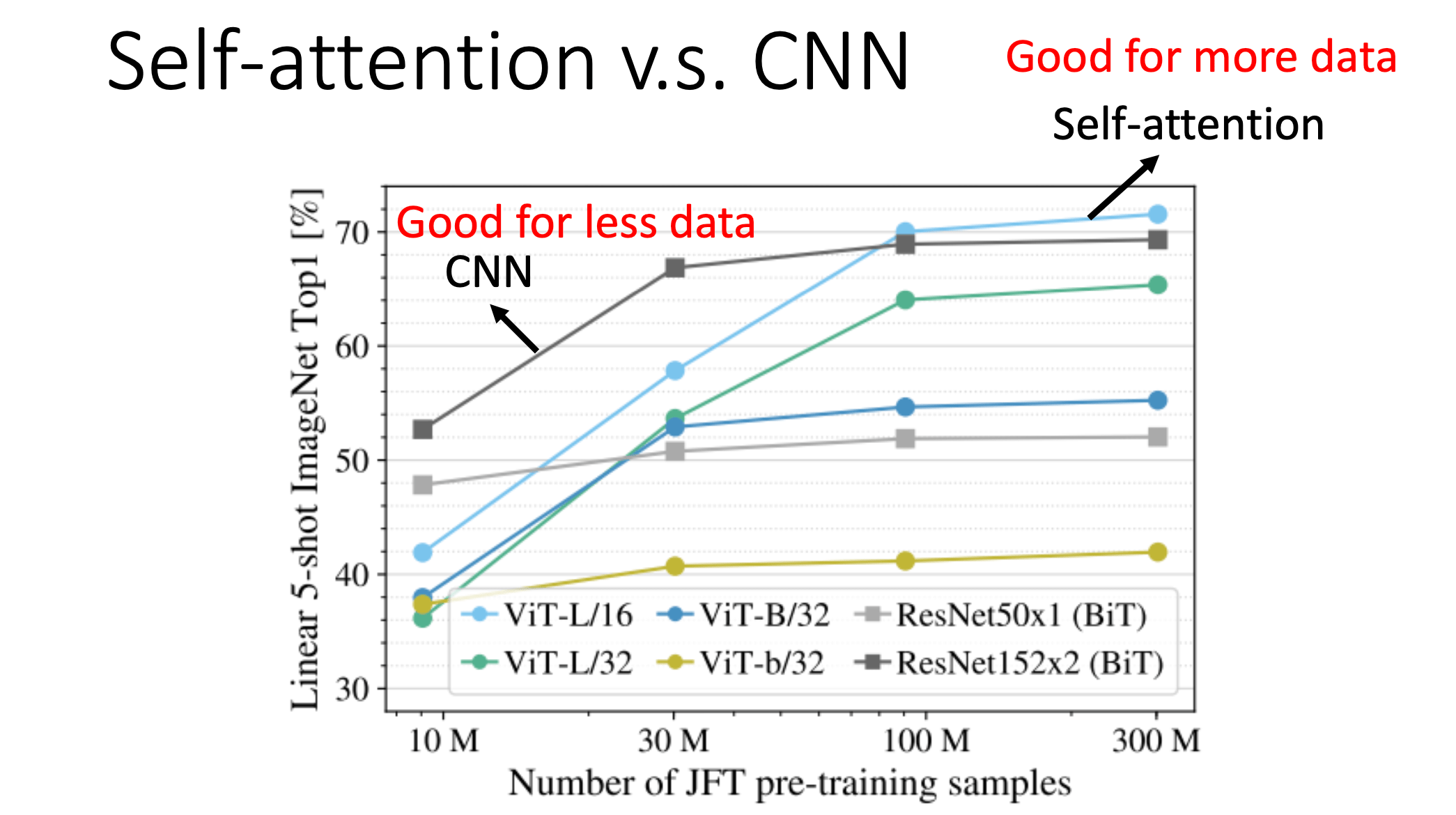
既然Self-attention比较灵活,那么我们知道比较灵活的模型,需要更多的数据,如果数据量不够就有可能overfitting
而小的模型(限制比较多的模型,它适合在数据量少的时候使用,因为它可能不容易overfitting,所以就提供了一种构建模型的思路,如果模型的限制设计得比较好,就会有不错的结果。
下面一篇论文比较了用不同的 data 量来训练 CNN 跟 Self-attention时的效果:
An Image is Worth 16x16 Words Transformers for Image Recognition at scale
Self-attention v.s. RNN
RNN:**上一个输入序列的输出用作下一个输入序列的输入 **——慢(但是 RNN 其实也可以是双向的)

Self-attention for Graph
图也可以看作是一堆向量,既然是一堆向量那么就可以用 Self-attention 来处理。所以 Self-attention 也可以用在图上面
但是把 Self-attention用在Graph 上面的时候有特别之处
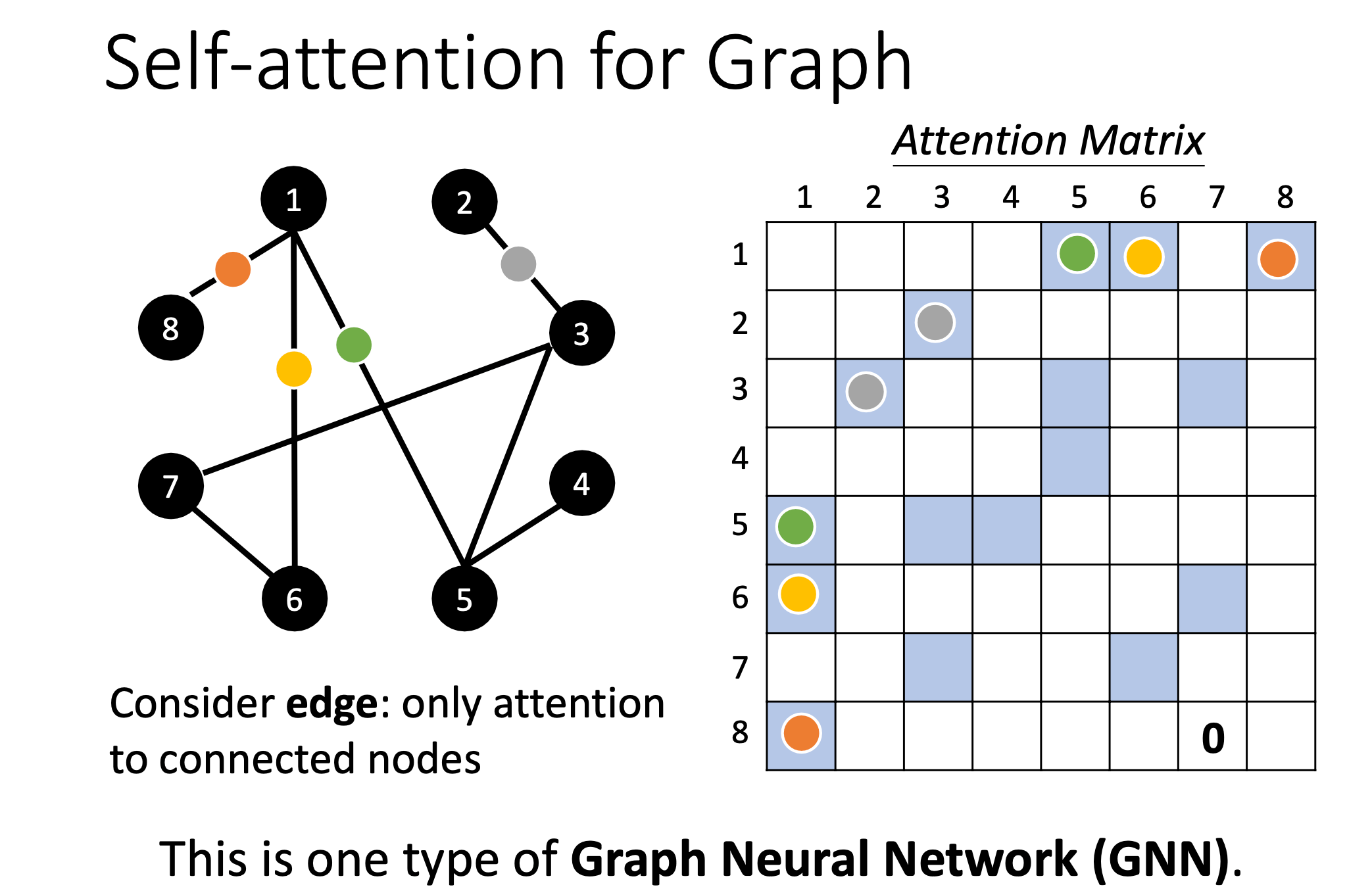
在Graph上面,每一个节点可以表示成一个向量。但不只有节点的信息,还有边的信息,我们知道哪些节点之间是相连的,也就是哪些节点是有关联的。
有了边的信息,那么节点之间的关联性就不需要通过算法学习的出,可以直接拿到节点之间的关联性。也就是说,使用Self-attention做Attention Matrix计算时,只需要计算有边相连的节点就好
若两个节点之间没有关系,我们就不需要再去计算它的 attention score,直接把它设为 0 就好
这种限制,用在 Graph 上面的时候,其实就是一种 Graph Neural Network,也就是一种 GNN。

More
Self-attention 有非常多的变形,论文《Long Range Arena: A Benchmark for Efficient Transformers》和《Efficient Transformers: A Survey 》里面做出了比较。
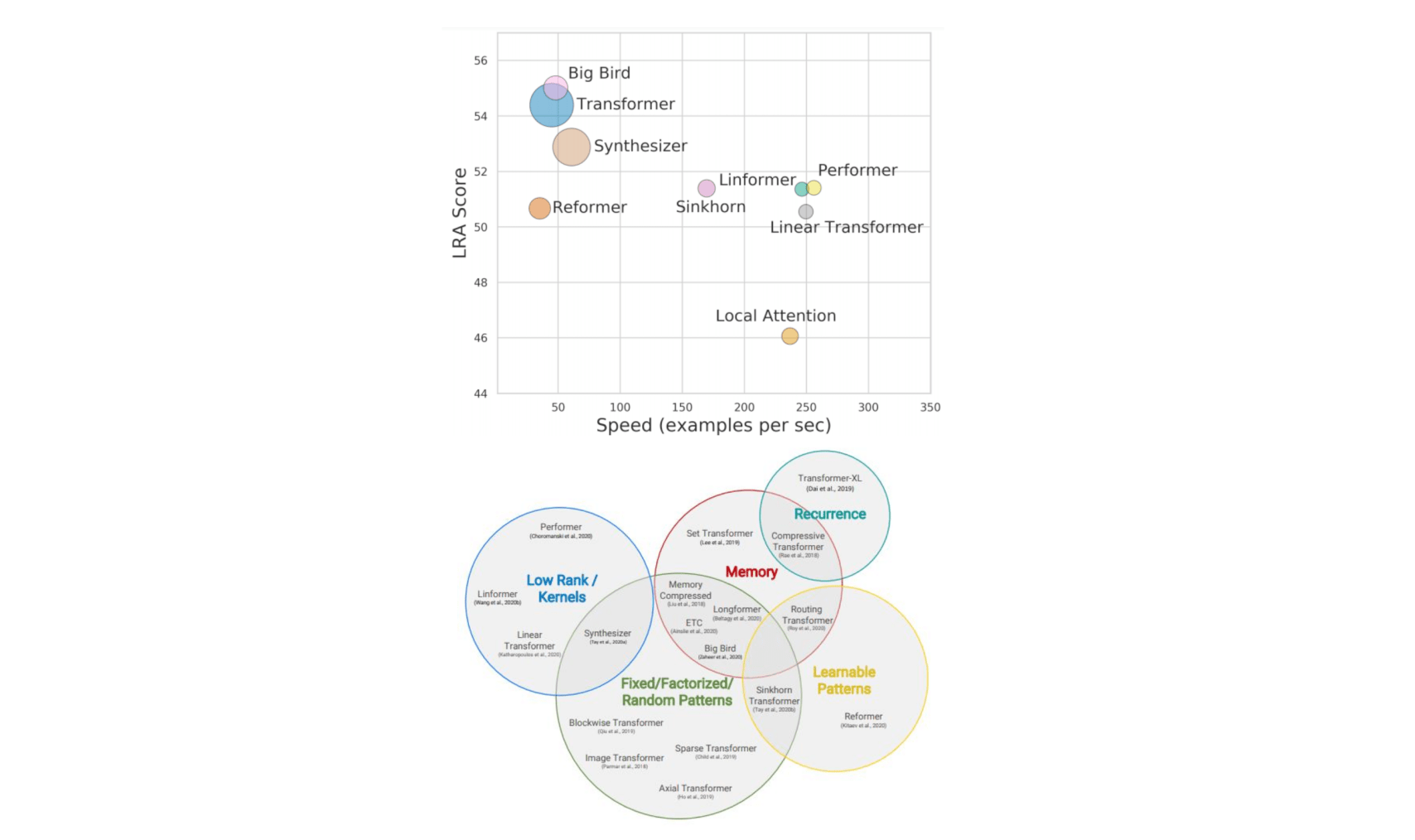
因为 Self-attention 最大的问题就是运算量非常地大,所以怎么样减少 Self-attention 的运算量,是一个未来的重点。
往右代表算法运算的速度,它们的速度会比原来的 Transformer 快,但是快的速度带来的就是performance 变差
这个纵轴代表是 performance,所以它们往往比原来的 Transformer表现得差一点,但是速度会比较快。