CNN卷积神经网络笔记
CNN卷积神经网络笔记
—— 专门用于图片
CNN卷积神经网络笔记
- 专门用于图片
- Alphatgo用的也是CNN
question: 给计算机一张图片,它是怎么识别出图片里有什么东西的?
先决条件:
- 输入模型的图片大小是固定的
- 对于大小不一的图片,一般先Rescale成大小相同的图片
question: 一张图片怎么样才能作为一个模型的输入?
输入向量
- 输入图像向量化
对于计算机而言,一张图片是一个三维的张量,第一、二维度代表图片的长和宽,还有一个维度代表Channel数目。
一张彩色的图片,每一个像素都是由RGB三个颜色组成,所以这三个Channel就代表了RGB三个颜色。
也就是说输入到模型的向量其实是代表一张图片的三维张量拉直的结果。
表示称一个One-Hot Vector

如果向量的长度是 2000,就代表说这个模型,可以辨识出 2000 种不同的东西,那今天比较强的影像辨识系统,往往可以辨识出 1000 种以上的东西,甚至到上万种不同的 Object
- Softmax归一化后输出
- 存在问题:假设第一层神经元数目有1000个,那么按照以上计算方法第一层的 Weight,就有 1000×100 × 100×3,也就是 3×10 的 7 次方,参数越多就会增加Overfitting过拟合的风险。https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/W14_PAC-introduction.pdf 从数学上证明模型的弹性越大,就越容易 Overfitting。
- 解决方法:我们不一定需要Fully Connected,不需要每个神经元跟每个输入的维度都有一个权重,可以共享权重参数
个人理解的CNN其实就是:盲人摸象
不需要每个神经元都去看一张完整的图片,只需要将图片的一小部分当作输入,就足以让神经元侦测到特别关键的Pattern出现。
举例来说 如果现在:
- 有某一个 Neuron ,它看到鸟嘴这个 Pattern
- 有某个 Neuron 又说,它看到眼睛这个 Pattern
- 又有某个 Neuron 说,它看到鸟爪这个 Pattern
也许看到这些 Pattern 综合起来就代表,我们看到了一只鸟,类神经网络就可以告诉你,因为看到了这些 Pattern,所以它看到了一只鸟。
特殊名词
Receptive Field
神经元的接受区域
每一个神经元只关注自己的Receptive Field里面的内容就好。单个神经元要做的事情就是把这 3×3×3 的数值拉直,变成一个长度27 维的向量,再把这 27 维的向量作为这个 Neuron神经元 的输入。
这个 Neuron 神经元会给 27 维的向量的每一个 Dimension 一个 Weight,所以这个 Neuron 有27个 Weight,再加上 Bias 得到的输出,这个输出再送给下一层的 Neuron 当作输入。

Stride
方框移动的量:Stride,往往是1或者2,超出范围就做Padding——补0
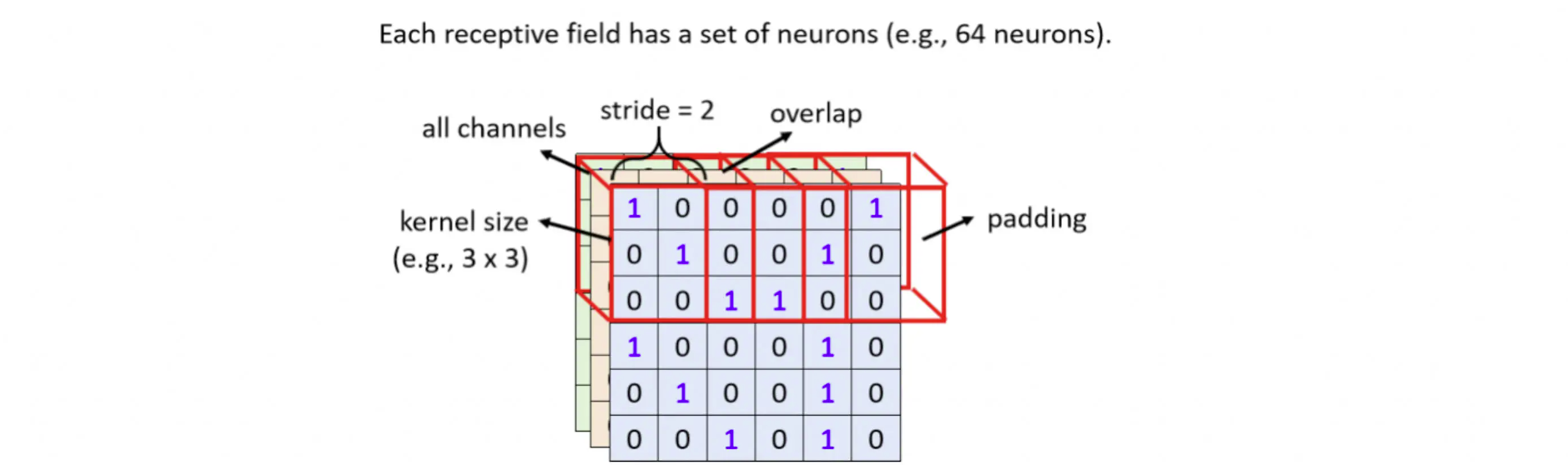
那么在方框移动的过程中,就会侦测到目标的特征形态
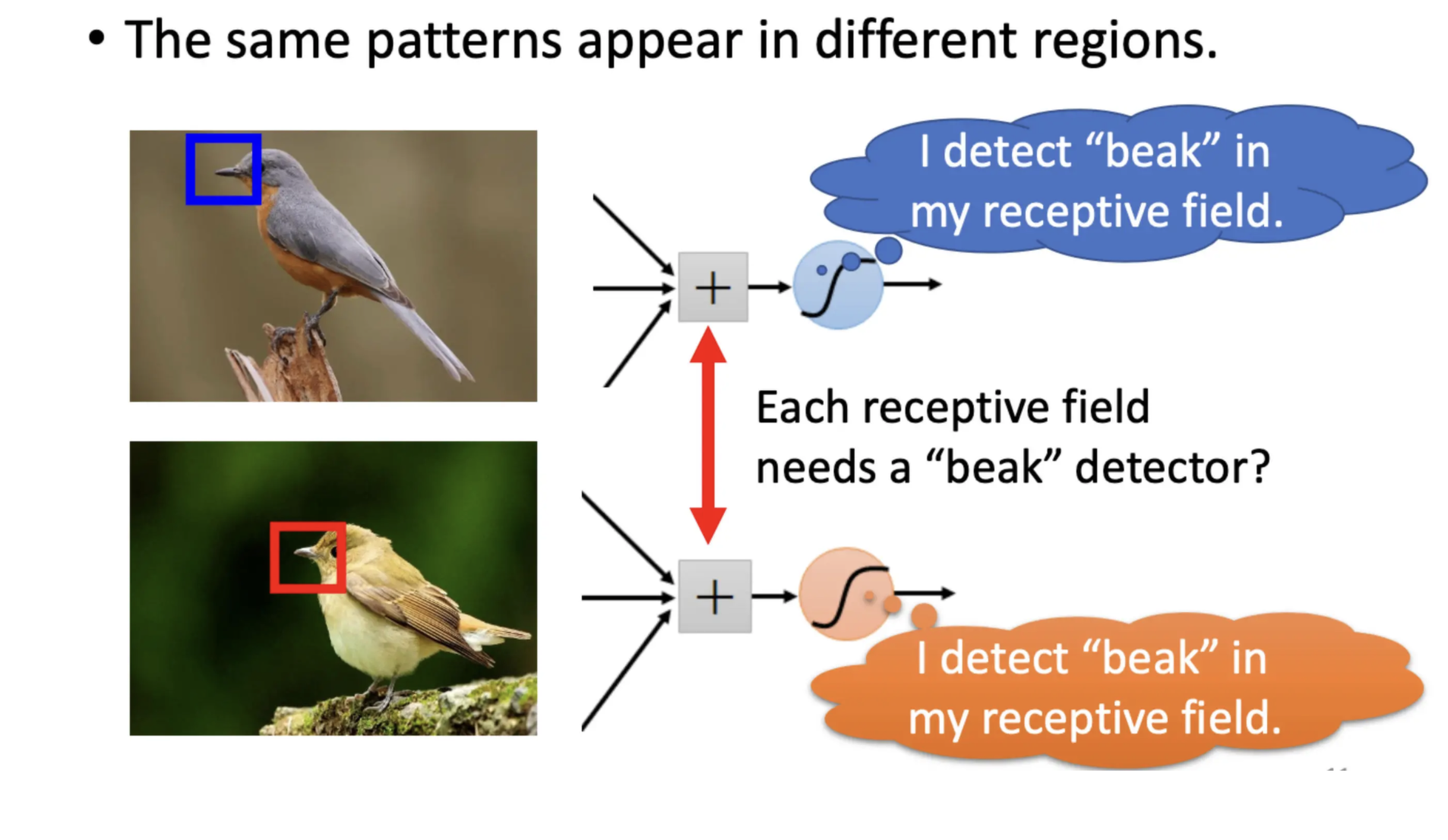
question: 目标的特征,如上图的鸟嘴可能出现在图片的不同位置。如果不同的Receptive Field侦测区域都需要一个侦测鸟嘴的神经元,那么参数量会非常庞大。
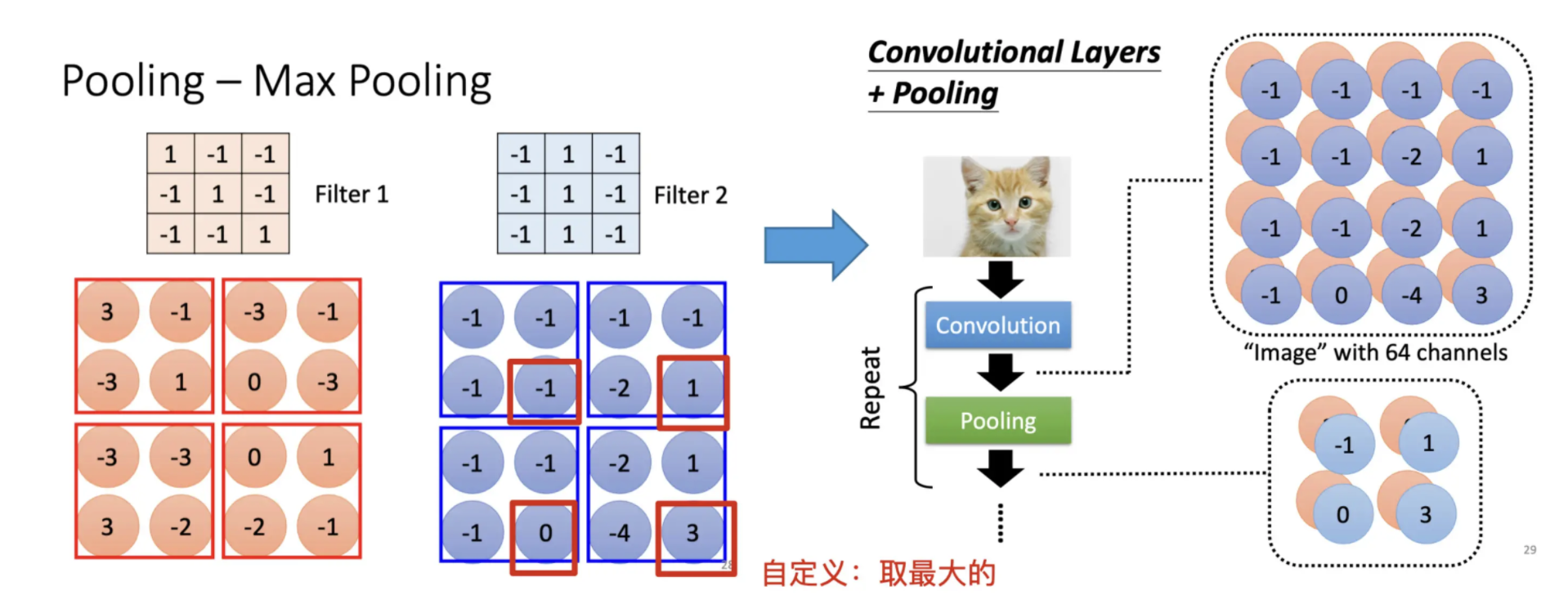
Pooling
减少运算量
Pooling 做的事情就是把图片变小
Parameter Sharing权值共享
所谓共享参数就是,这两个Neuron 它们的 weights完全是一样的
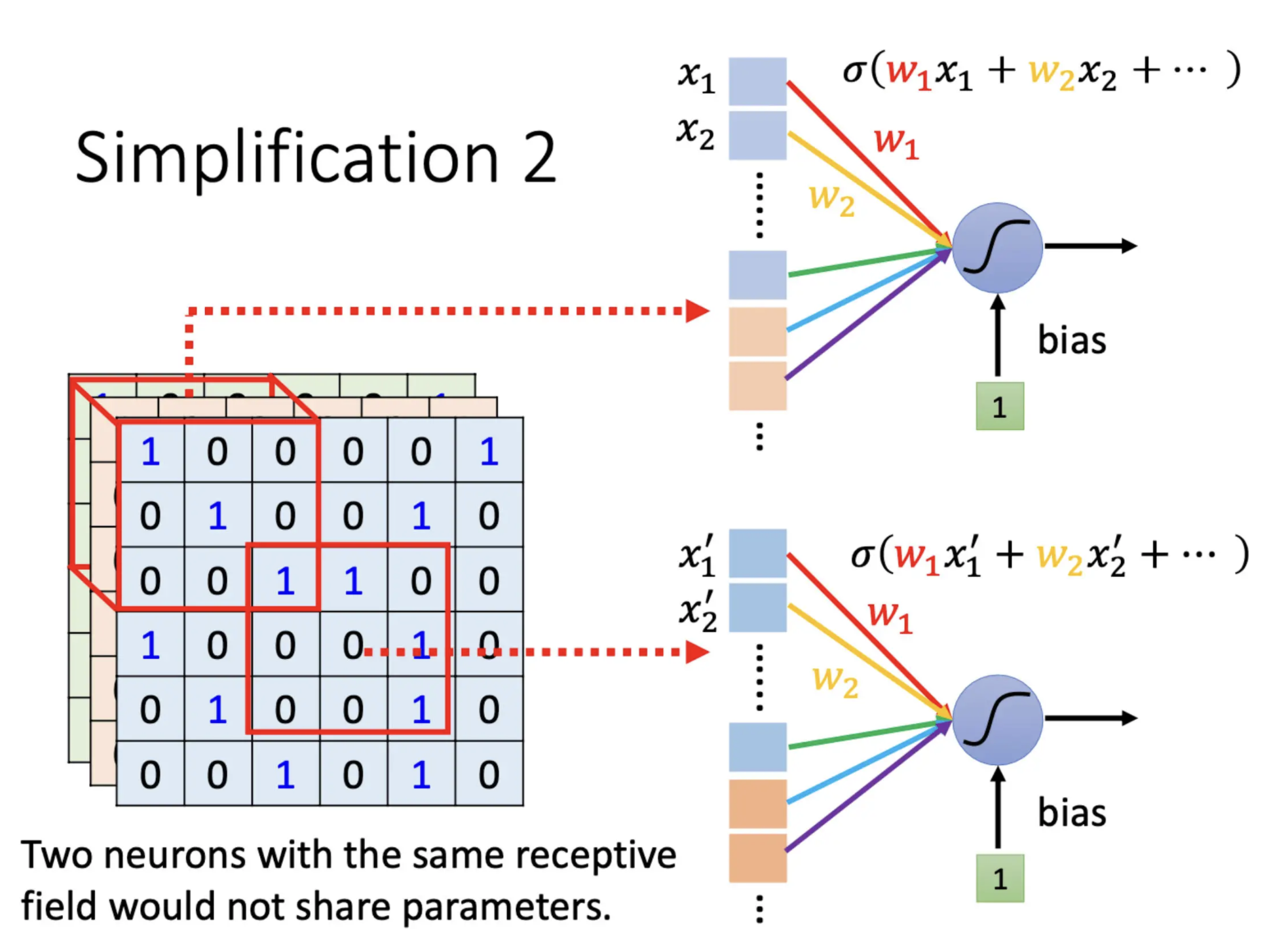
上面这个 Neuron 跟下面这个 Neuron,它们守备的 Receptive Field 是不一样的,但是它们的参数是一模一样的。
但是他们的输出是不一样的,因为输入不一样。
共享参数方法
每一个 Receptive Field,它都有一组 Neuron 在负责守备
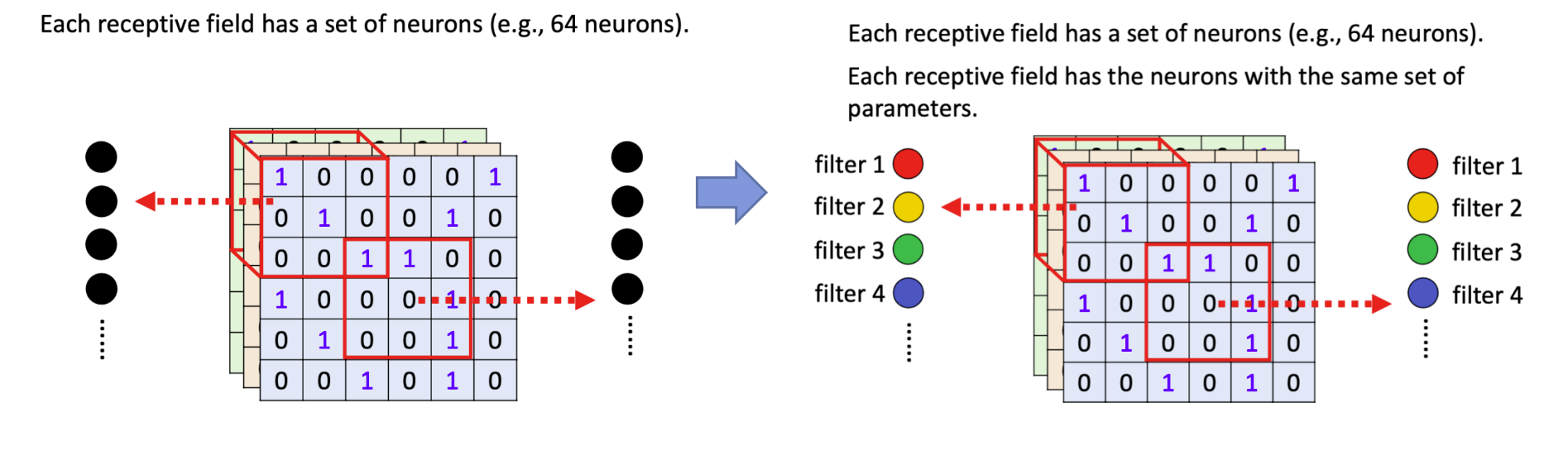
用同样的颜色代表两个神经元共享同样的参数。
所以其实每一个 Receptive Field都只有一组参数而已,就是
- 左上边这个 Receptive Field 的第一个红色 Neuron,会跟右下边这个 Receptive Field 的第一个 红色Neuron 共用参数
- 它的第二个橙色 Neuron,跟它的第二个 橙色Neuron 共用参数
- 它的第三个绿色Neuron,跟它的第三个绿色 Neuron 共用参数
- 所以每一个 Receptive Field,都只有一组参数而已
那这些参数有一个名字叫做 Filter,所以这两个红色 Neuron,它们共用同一组参数,这组参数就叫 Filter1,橙色这两个 Neuron 它们共同一组参数,这组参数就叫 Filter2 叫 Filter3 叫 Filter4,以此类推。
Benefit of Convolutional Layer
以上内容都是为了让神经网络的弹性变小。Fully Connected 的 Network是最大的
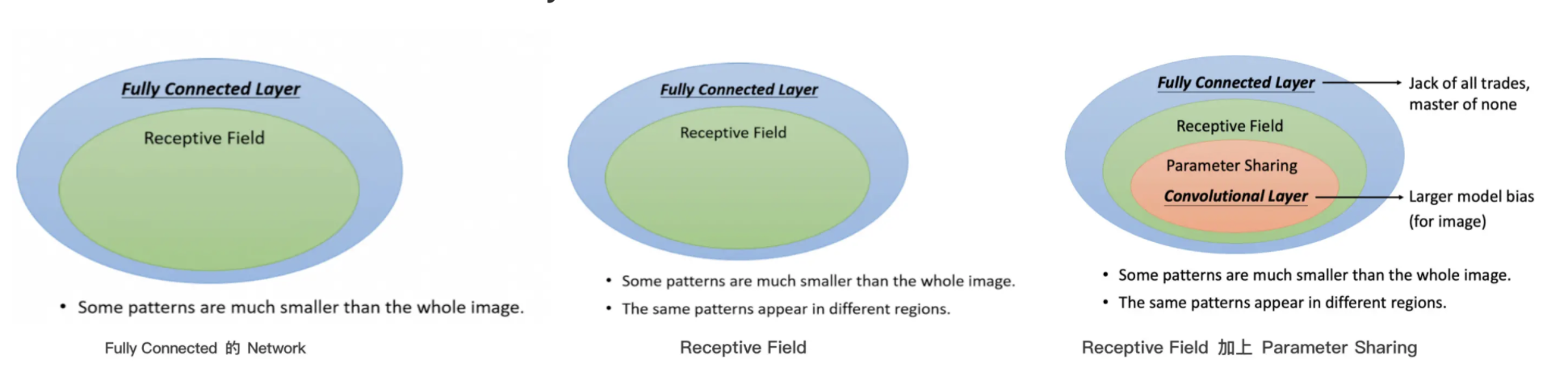
- 以上内容让我们了解到,不需要看整张图片,只看图片的一小部分就可以侦测出重要的Pattern,这就是Receptive Field的概念
- 加入参数共享以后,就意味着某一些 Neuron参数要一模一样,所以这又更增加了对 Neuron 的限制,而 Receptive Field 加上 Parameter Sharing,就是 Convolutional Layer。
从上图明显看出CNN 的 Bias 比较大,也就是Model 的 Bias 比较大。
question: Model Bias 大,不是一件坏事吗?
- Model Bias 大,不一定是坏事
- 因為当 Model Bias 小,Model 的 Flexibility 很高的时候,它比较容易 Overfitting,Fully Connected Layer全连接层可以做各式各样的事情,它可以有各式各样的变化,但是它可能没有办法在特定的任务上做好。
- 而 Convolutional Layer,它是专门为图片设计的。Receptive Field 、参数共享都是为图片设计的。所以它在图片上可以做得好。虽然它的 Model Bias 很大,但这个在影像上不是问题,但是如果它用在图片之外的任务,就要仔细想想,那些任务有没有图片的特性。
question: 形成一个个repective field之后,神经元如何识别出里面的pattern?
滑动分块之后Convolutional 的 Layer 里面有很多的 Filter,也就是神经元对应的函数,将repective field里面的数值作为输入,输出结果就是预测结果。
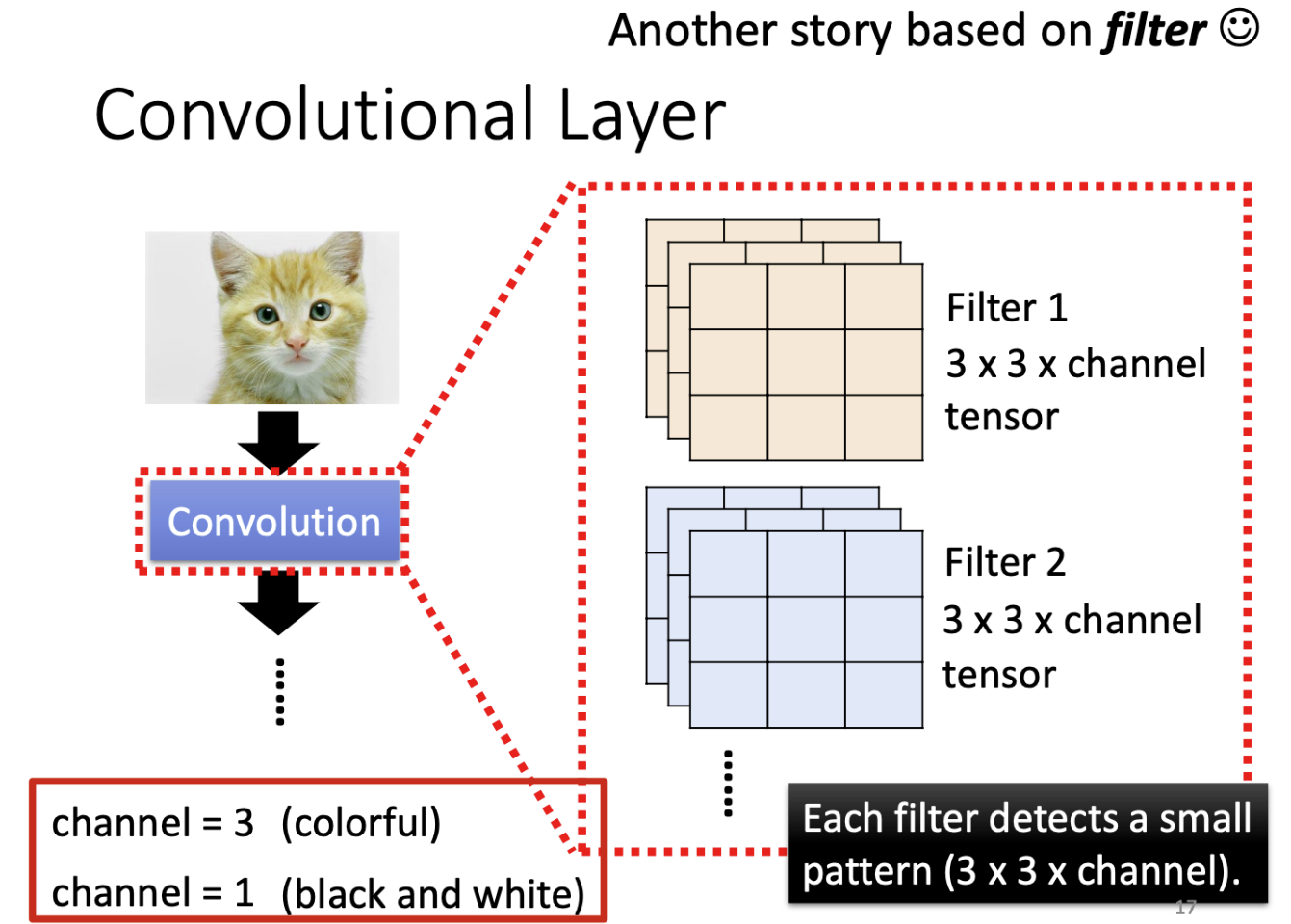
这些Filter的大小是3 × 3 × Channel,如果是彩色图片的话,那就是 RGB 三个 Channel,如果是黑白的图片的话,它的 Channel 就等于 1。
例:
- 假设一张图片黑白,也就是说Channel = 1
- Filter内的参数已知(已经完成gradient decent)
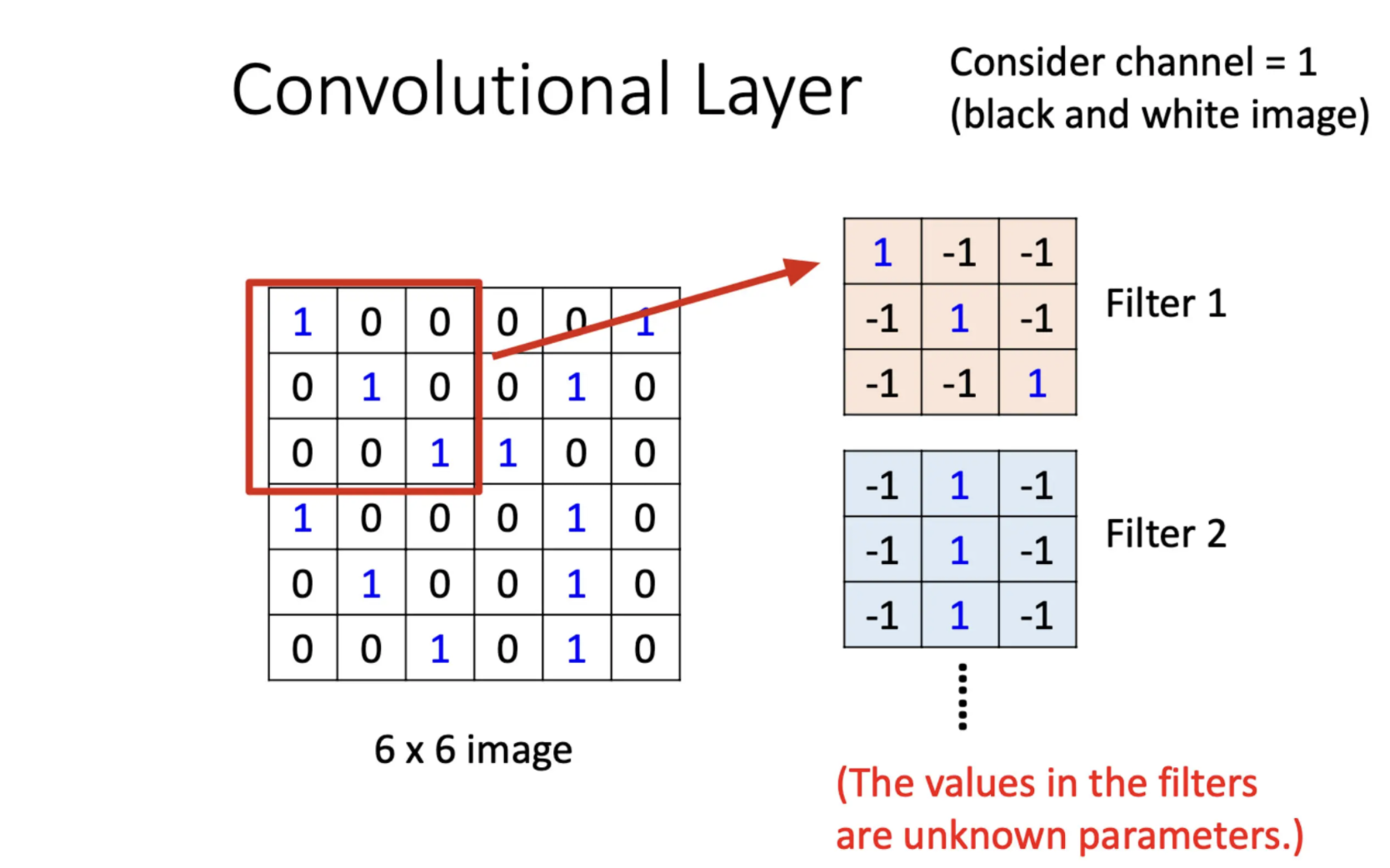
一张6 × 6 × 1的图片可以划分为多个Recptive Field,对于任意一个Filter,依次滑过各个Recptive Field。
对于第一个Recptive Field,将矩阵里面所有的值,跟 Filter 里面的 9 个值做内积,做完是 3。
注意!
在此处卷积运算中的内积,不是线性代数中矩阵的乘法,而是filter跟图片对应位置的数值直接相乘,所有的都乘完以后再相加
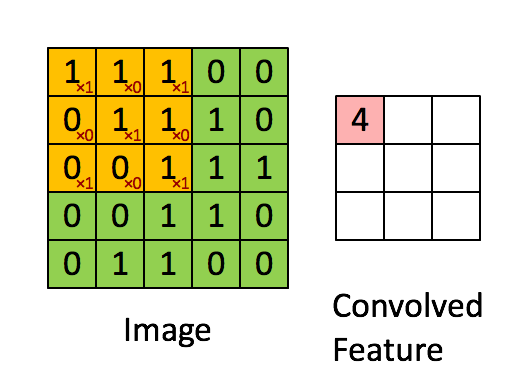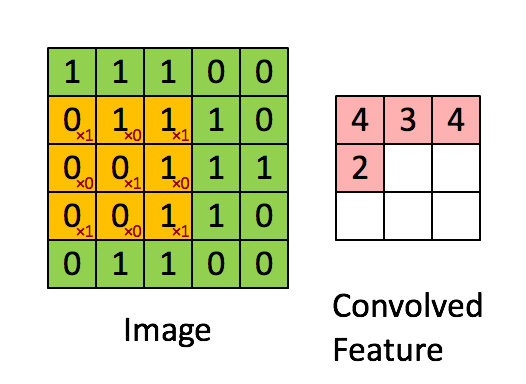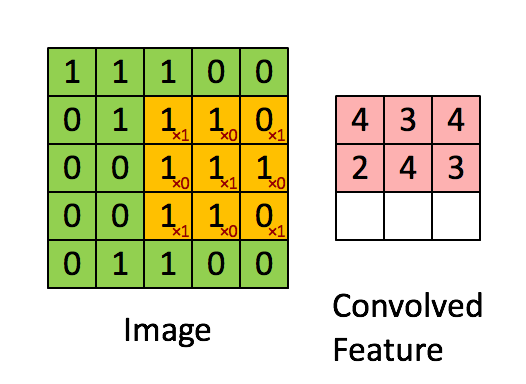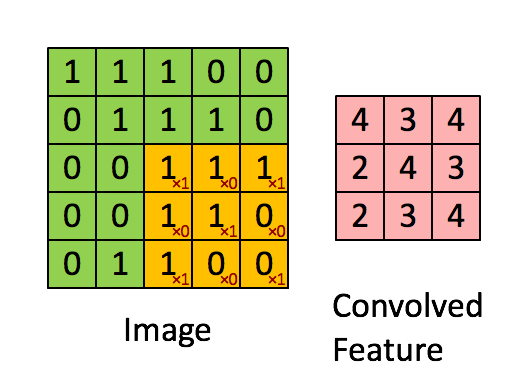
把每一个 Filter,都重复以上流程,先从左上角开始扫起,得到一个数值,往右移动Stride个距离,再得到一个数值,再往右移Stride,再得到一个数值,重复同样的操作,直到把整张图片都扫完,又得到另外一组数值。
每一个 Filter,都会得到一群数字。如果有 64 个 Filter,就得到 64 群的数字,那这一群数字被叫做Feature Map
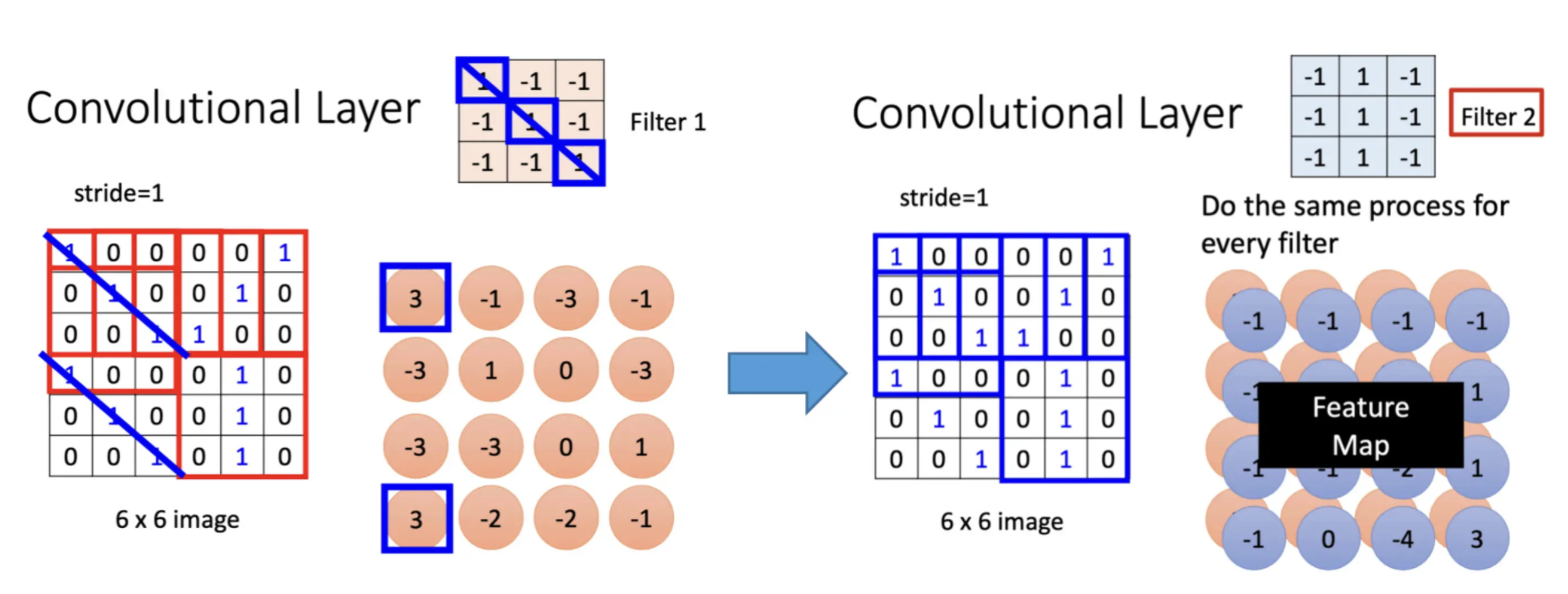
Feature Map可以看作是一张新的图片,新的图片里面每一个Channel都对应原来图片的Filter作用于Recptive Field得到的一群数字。本来一张图片它有三个 Channel,通过一个 Convolution之后,它变成一张新的图片,有 64 个 Channel。
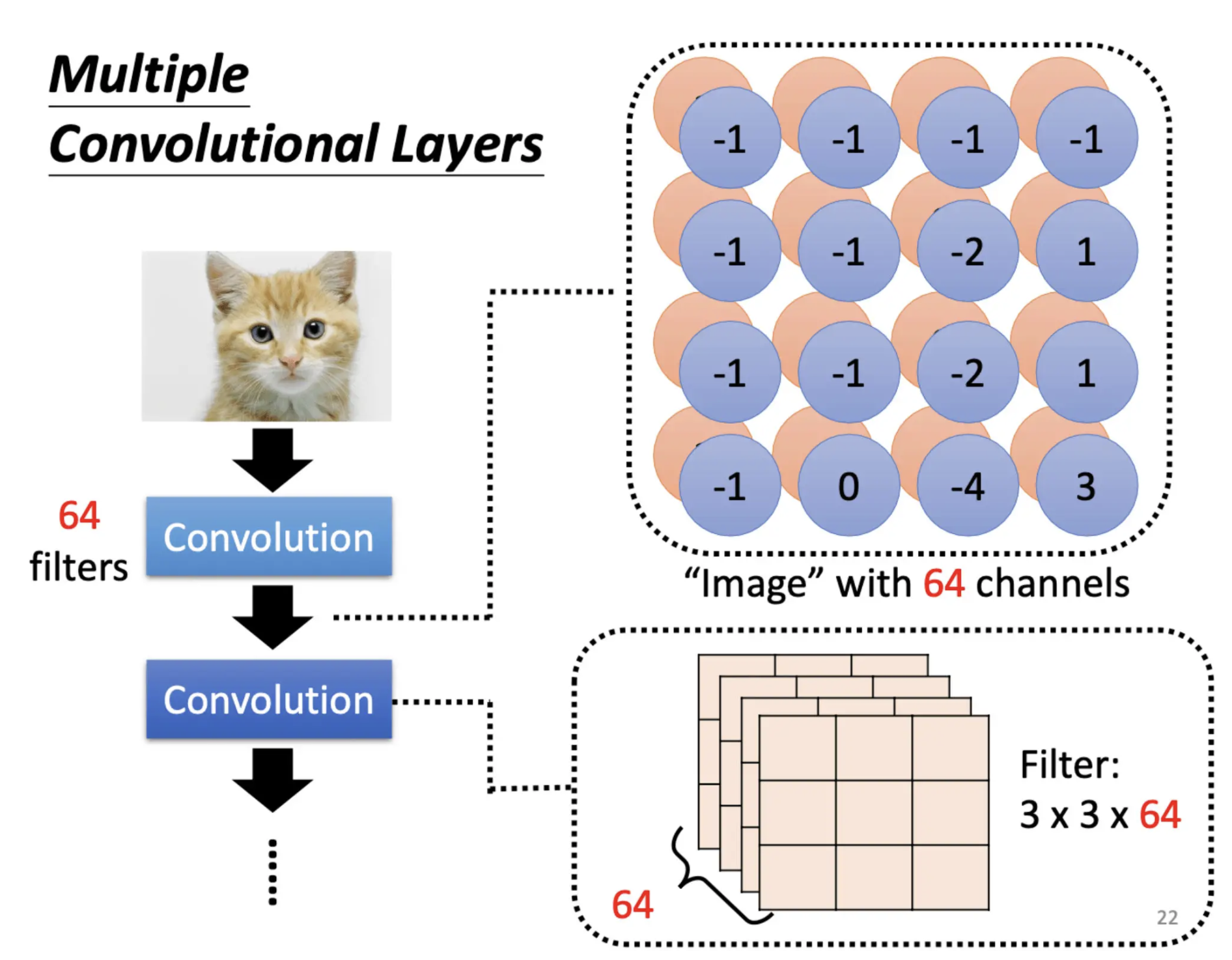
Convolutional Layer 可以叠很多层,第二个卷积层的Filter同样设3 × 3,且高度必须为64。也就是Feature Map图片的信道个数。
Filter 的高度就是要处理的图片的 Channel,所以跟刚才第一层的 Convolution一样,假设输入的图片是黑白的那么 Channel是 1,Filter 的高度就是 1,输入图片是彩色的 Channel 是 3,那 Filter 的高度就是 3。
在第二层里面,我们也会得到一张图片,对第二个 Convolutional Layer 来说,它的输入也是一张图片。那这个图片的 Channel 是多少,这个图片的 Channel是前一个 Convolutional Layer 的Filter 数目。前一个 Convolutional Layer Filter 数目 64,那输出以后就是 64 个 Channel。
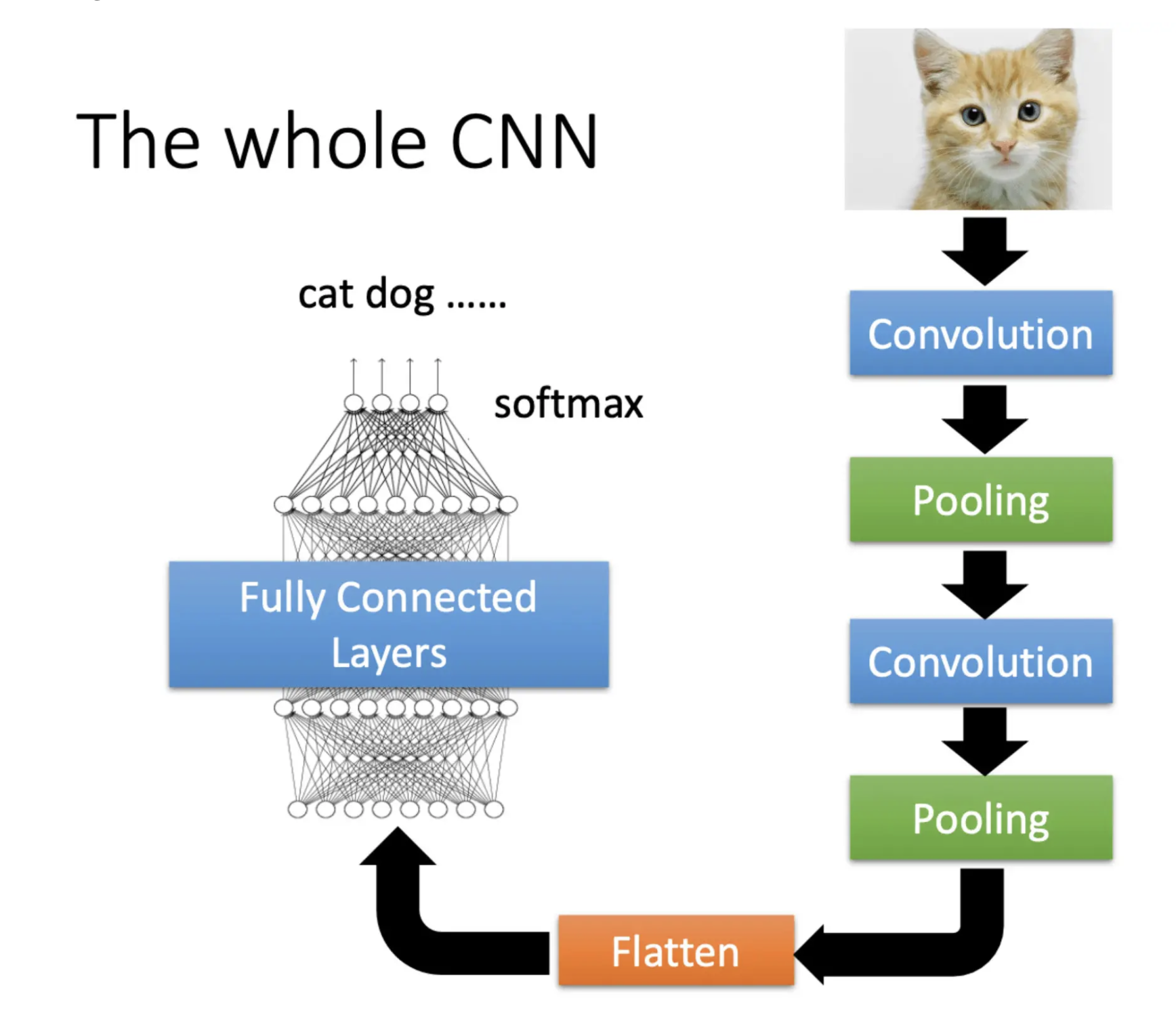
CNN完整流程
- Pooling不是必须的,只是为了减少运算量。
不足
- 将一张图片放大后给CNN模型识别一样识别不出来
因为图片放大后图片的向量里面的数值就发生了变化,对于CNN来说是不认识的图片。
所以 CNN 并没有想像的那么强,那就是为什么在做影像辨识的时候,往往都要做 Data Augmentation,所谓 Data Augmentation 的意思就是把训练资料,每张图片都截一小块出来放大,让 CNN 有看过不同大小的 Pattern,然后把图片旋转,让它知道某一个物件旋转以后是什么样子,CNN 才会做到好的结果。