
数据开发岗位实习经历
数据开发岗位实习
清明节后入职广州某互联网公司从事数据开发工程师工作(实际上就是爬虫开发),因为我个人的原因8月提出离职。在职四个月期间主要完成了全国所有全国源、地方源的企业信息公示系统的爬虫。 在这里得益于两位yang哥还有大数据组其他同事的帮助,我学到了很多知识。而相比于技术,平时和他们交流时学到的面对问题时的思维方式,对我来说更加重要,让我面对工作甚至生活中的难题时,能够更好地解决问题,这是一笔不可估量的财富。
让我最享受的还是这四个月里一个人生活、学习的快乐,或许再过几年我就要面对家庭、生存的压力,前途是未知的,而我对当下是满足的,所以这段时间的收获我打算慢慢记下来。人不能一直满足现状,也不能永远饥渴。罗马不是一天建成的,我觉得人最重要的是沉淀,知识的沉淀,财富的沉淀,思维的沉淀。
基于浏览器的爬虫
- 结论: 基于浏览器的爬虫大多都无法用于生产环境
读书时自学爬虫,遇到淘宝1688、天猫等反爬手段很强的网站时,往往会想到使用selenium爬取,而市面上也有很多基于浏览器的爬取工具如八爪鱼、后羿等工具。但是这些难以应用到生产环境,因为:
- 速度慢:浏览器会加载大量无关的请求、无关的js,浏览器会将html渲染成DOM树;
- 难以调试、无法保证成功率;
- 所有通过浏览器执行的前端程序,都可以用代码实现。
爬虫框架
- Scrapy
- 最常用的Python爬虫框架,比较灵活
- Pyspider
- 分布式Python爬虫框架,追求存储所有历史爬取链接,并自动更新
- Crawler.js
- 简单易用的Node爬虫框架
- Nutch
- Apache的分布式爬虫,搜索引擎友好
框架分类:
- 精准型:Scrapy,Crawler.js
- 撒网型:Pyspider,Nutch
Scrapy介绍
scrapy架构图
来源: scrapy
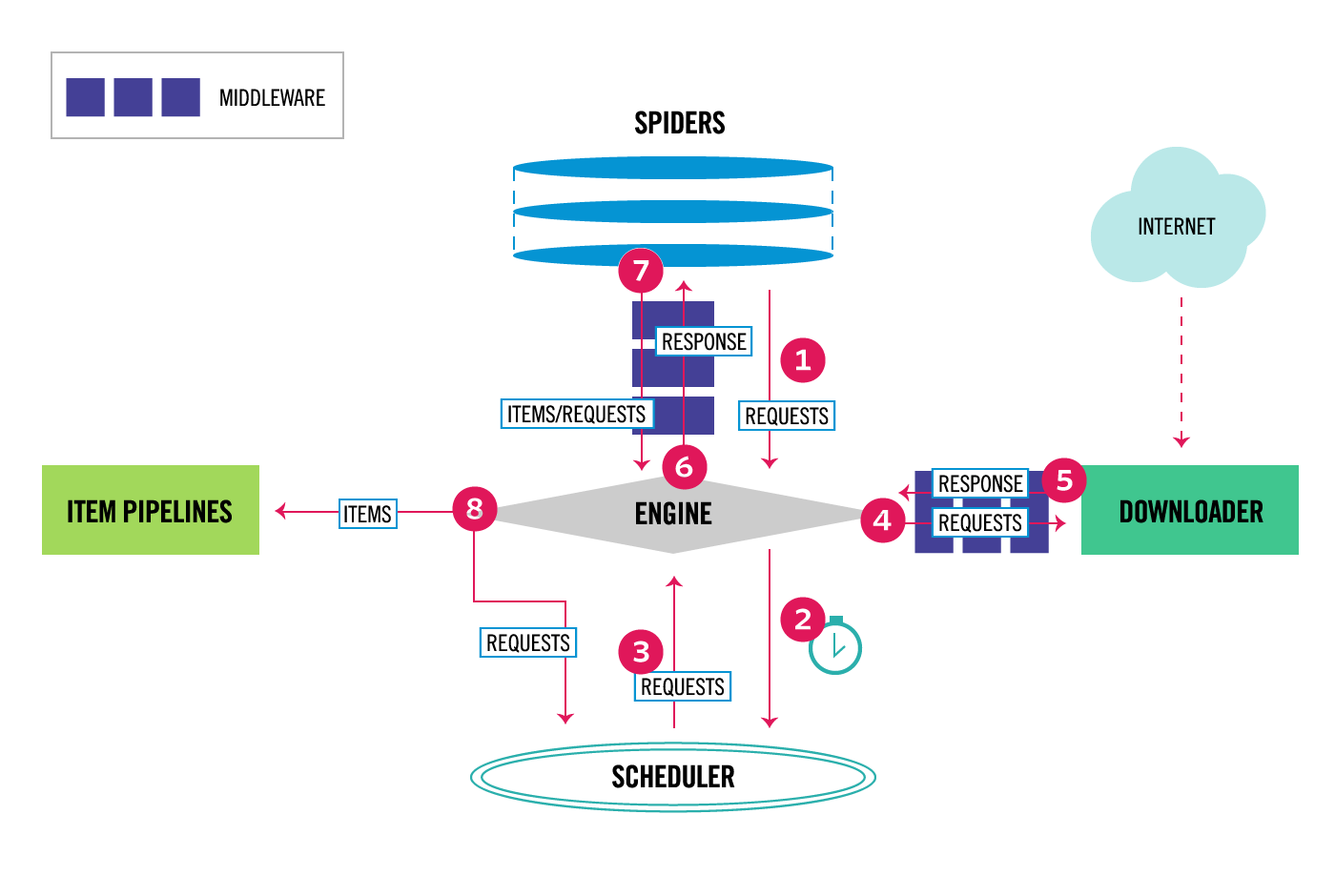
scrapy 可以分为以下几个部分:
- ENGINE。 爬虫引擎,从 Spider 获取要抓取的初始请求。负责处理整个系统的数据流处理、触发事务,是整个框架的核心。
- ITEM。项目,定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象。Scrapy 通过 itemadapter 库支持以下类型的项目:字典、项目对象、数据类对象和 attrs 对象。
- Scheduler。 调度器,接受ENGINE发送过来的请求,并且将其加入Redis队列中,在稍后ENGINE再次请求时将请求提供给ENGINE。
- Downloader。 下载器,负责下载网页并将它们提供给ENGINE,然后ENGINE再将它们提供给SPIDERS。
- SPIDERS。 定义了爬取的逻辑规则和页面解析规则,负责解析响应并且声称提取结果和新的请求。实际上,爬取和解析应该分离,爬取较快,解析较慢,合理的框架应该是先爬取再解析以提高速度。
- ITEM PIPELINES。 负责处理由Spider从网页中抽取的项目,主要负责清洗、验证和存储数据。
- DOWNLOADER MIDDLEWARES。 下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求和响应。
- SPIDER MIDDLEWARES。 spider中间件,位于ENGINE和Spider之间的钩子框架,主要处理Spider输入的响应和输出结果以及新的请求。
数据流
- 引擎首先打开一个网站,找到处理该网站的Spider,从 Spider 获取要抓取的初始请求。
- 引擎从 Spider 获取第一个要爬取的URL,在调度器中以Request的形式调度请求
- 引擎向调度器请求下一个要爬取的URL。
- 调度程序将下一个要爬取的URL返回给引擎,引擎通过下载器中间件将URL转发给下载器。
- 引擎将请求通过下载器中间件发送到下载器,一旦页面完成下载,下载器生成一个响应(带有该页面)并将其通过下载器中间件发送到引擎。
- 引擎从下载器接收Response并通过Spider中间件将其发送给Spider进行处理。
- Spider 处理Response并将抓取的Item和新的Request通过 Spider 中间件返回给引擎。
- 引擎将处理后的Item发送到Item pipeline,然后将处理后的Request发送到调度程序并询问下一个请求进行爬取。
- 该过程重复(从第 2 步开始到第8部),直到不再有来自调度程序的请求。
通过多个组件相互协作、不同组件完成的工作不同、组件对异步处理的支持,最大限度地利用了网络带宽,提高了数据爬取和处理的效率。
优缺点
优点
- 基于 Twisted,异步高并发
- 灵活,可编程性高,中间件可定制
- 搭配 scrapy-redis 后可以分布式部署
缺点
- 每个爬虫都是一个进程,无法集中管理
- 无法动态分配资源,协调爬虫间优先级
- 每调整一个参数都要重启爬虫
- IO跟CPU运算绑定,性能不足只能水平扩展
- 内存占用高
PySpider
来源:pyspider
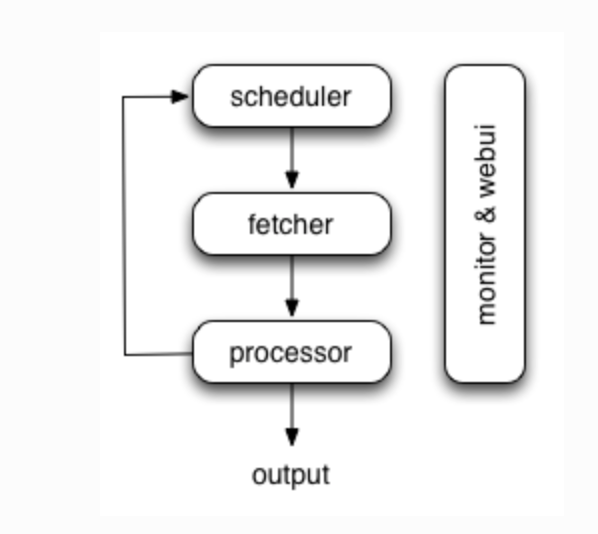
优缺点
优点
- 基于 Tornado,异步高并发
- 有一个方便脚本编写的WebUI
- 分布式部署,IO跟CPU密集型组件分离
- 保存所有历史请求,过期自动重爬
- 集中管理多爬虫
缺点
- 难以跟踪爬取进度,只适合广撒网型爬虫
- 模式固定,难以扩展
- 调度器为单进程,容易出现瓶颈
- 存储所有请求,数据库读写容易出现瓶颈
- 使用数据库做优先级排序与去重,容易出现瓶颈
- 难以对爬虫做代码版本管理
- 无法在爬取过程中输出日志,难以统计监控
- 无法对多爬虫进行优先级调度
Pyspider的优化版本PyspiderX & PyspiderHub
PyspiderX 是 Pyspider的改进版本:
- 去掉了成功连接的数据库存储,减轻数据库的存储压力
- 去掉启动时,加载所有历史请求的操作
- Redis去重
- 修复其他已知问题
- 对接PyspiderHub
PyspiderHub 是一个多 Pyspider 集群管理器:
- 提供一个集中显示所有 Pyspider 集群运行状态的WebUI
- 提供针对一个 Pyspider 集群中的爬虫优先级调度(通过定时停止和启动爬虫)
- 自动获取某个节点的负载,以便用户更好的分配资源
工作用的爬虫系统
- 结合了多种爬虫框架的优点,dalao牛逼
- 过于先进,不便展示
重点
待更新。。